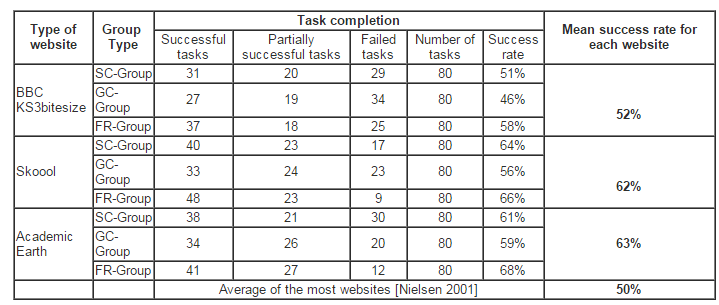
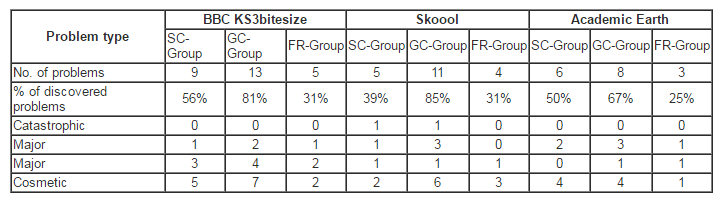
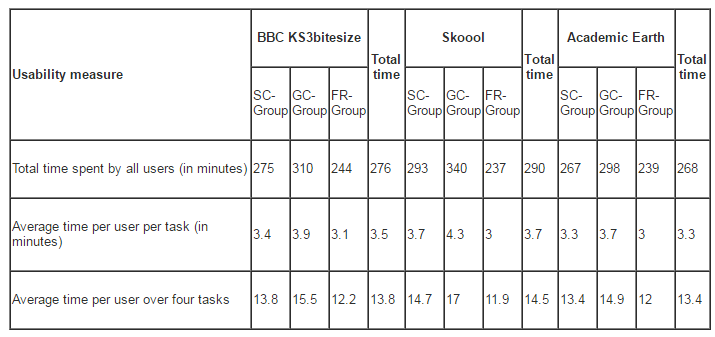
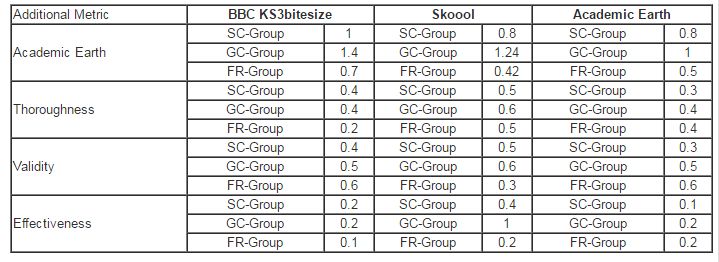
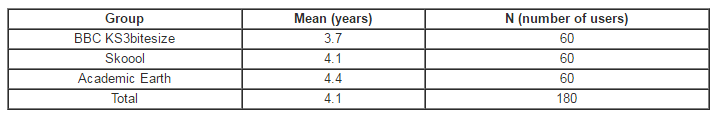This paper investigated the impact on the results of usability testing in using three combinations of three tasks and three ‘think-aloud’ approaches. These combinations are a specific task with ‘constructive interaction think-aloud’, ‘guess task with concurrent think-aloud’ and, finally, ‘free task with retrospective think-aloud’. It has been shown that having different combinations of task design and ‘think-aloud’ approach can affect usability testing results by discovering different usability problems. This was demonstrated through the results of the assessment of the sites’ usability obtained from the experiment in terms of the problems found. However, the study proves that there is no need to design complex task scenarios to discover more usability problems or to employ ‘think-aloud’ approaches. Designing suitable tasks based on the website features and understanding the users’ experiences is quite sufficient to obtain good results. Further investigation on how different combinations of task design and think-aloud approaches can affect usability testing results is needed to confirm the findings of this research. In this regard, we propose to examine the impact of employing different combinations of ‘think-aloud’ approaches and task designs; for example, employ the ‘specific task’ with the ‘retrospective think-aloud’ type or the ‘guess task’ with the ‘constructive interaction think-aloud’ type, and also to employ these same combinations on different websites.
Acknowledgements
We thank the expert evaluators at the School of Education and Lifelong Learning and the School of Computing Sciences at the University of East Anglia (UEA), and the MSc and PhD students at both these schools, and also at the Saudi Norwich School (UK) and Thaghr School in Saudi Arabia. Thanks also go to the expert evaluators in Aviva company in the UK for their participation in this comparative study and in the mini-usability testing experiments.
References
Al-Badi, A., Michelle, O. Okam, Al Roobaea, R., and Mayhew, P. (2013), “Improving Usability of Social Networking Systems: A Case Study of LinkedIn,” Journal of Internet Social Networking & Virtual Communities, Vol. 2013 (2013), Article ID 889433, DOI: 10.5171/2013.889433.
Publisher
Alghamdi,A., Al-Badi, A., Al Roobaea, R., and Mayhew, P. (2013). A Comparative Study of Synchronous and Asynchronous Remote Usability Testing Methods. International Review of Basic and Applied Sciences. Vol. 1 Issue.3.
Alrobai, A., AlRoobaea, R., Al-Badi, A., and Mayhew, P. (2012). Investigating the usability of e-catalogue systems: modified heuristics vs. user testing, Journal of Technology Research.
AlRoobaea, R., Al-Badi, A., and Mayhew P. (2013). A Framework for Generating Domain-Specific Heuristics for Evaluating Online Educational Websites. International Journal of Information Technology & Computer Science, Volume 8, page 75 – 84.
AlRoobaea, R., Al-Badi, A., and Mayhew P. (2013). A Framework for Generating Domain-Specific Heuristics for Evaluating Online Educational Websites- Further Validation. International Journal of Information Technology & Computer Science, volume 8, page 97 – 105.
AlRoobaea, R., Al-Badi, A., and Mayhew, P. (2013). Generating a Domain Specific Inspection Evaluation Method through an Adaptive Framework: A Comparative Study on Educational Websites. International Journal of Human Computer Interaction (IJHCI), 4(2), 88.
AlRoobaea, R., Al-Badi, A., and Mayhew, P. (2013). Generating a Domain Specific Inspection Evaluation Method through an Adaptive Framework. International Journal of Advanced Computer Science and Applications, Vol.4 No.6.
Alshamari, M. and Mayhew, P. (2008). Task design: Its impact on usability testing. In Internet and Web Applications and Services, 2008, ICIW’08. Third International Conference on, pages 583-589. IEEE.
AlShamari, M., and Mayhew, P. (2010). Task Formulation in Usability Testing (Doctoral dissertation, University of East Anglia).
Dale, O., Drivenes, T., Tollefsen, M., and Reinertsen, A. (2012). User Testing of Social Media—Methodological Considerations. In Computers Helping People with Special Needs (pp. 573-580). Springer Berlin Heidelberg.
Publisher – Google Scholar
Dix, A. (2004). Human-computer interaction. Prentice Hall.
Dumas, J. and Redish, J. (1999). A practical guide to usability testing, Lives of Great Explorers Series, Intellect Books, Portland.
Ebling, M. and John, B. (2000). On the contributions of different empirical data in usability testing. In Proceedings of the 3rd Conference on Designing Interactive Systems: processes, practices, methods and techniques, pages 289-296. ACM.
Fang, X., and Holsapple, C. (2011). Impacts of navigation structure, task complexity, and users’ domain knowledge on Web site usability–an empirical study. Information Systems Frontiers, 13(4), 453-469.
Publisher – Google Scholar
Feng, J., Lazar, J., Kumin, L. and Ozok, A. (2010). Computer usage by children with Down’s syndrome: Challenges and future research. ACM Transactions on Accessible Computing (TACCESS), 2(3): 13.
Publisher – Google Scholar
Fernandez, A., Insfran, E. and Abrahão, S., (2011), Usability evaluation methods for the web: A systematic mapping study, Information and Software Technology.
Publisher – Google Scholar
Garrett, J. (2010). The elements of user experience: user-centered design for the Web and beyond. New Riders Pub.
Hornbaek, K. (2006). Current practice in measuring usability: Challenges to usability studies and research. International journal of human-computer studies, 64(2): 79-102.
Publisher – Google Scholar
ISO ISO. 9241-11: 1998 ergonomic requirements for office work with visual display terminals (vdts) – Part 11: guidance on usability. Geneve, CH: ISO, 1998.
Jeffries, R., Miller, J.R., Wharton, C. and Uyeda, K.M. (1991). User interface evaluation in the real world: A comparison of four techniques. Proceedings of ACMCHI’91, pp. 119-124. New York: ACM Press.
Khajouei, R., Hasman, A. and Jaspers, M., (2011), Determination of the effectiveness of two methods for usability evaluation using a CPOE medication ordering system, International Journal of Medical Informatics, vol. 80 (5), pp. 341-350.
Publisher – Google Scholar
Krahmer, E. and Ummelen, N. (2004). Thinking about thinking aloud: A comparison of two verbal protocols for usability testing. Professional Communication, IEEE Transactions on, 47(2): 105-117.
Law, L. and Hvannberg, E. (2002), complementarily and convergence of heuristic evaluation and usability test: a case study of universal brokerage platform. In Proceedings of the Second Nordic Conference on Human-Computer Interaction, pages 71-80, ACM.
Publisher – Google Scholar
Lewis, C. and Polson, P. (1992). Cognitive walkthroughs: A method for theory-based evaluation of user interfaces. Paper presented at the Tutorial at the CHI’92 Conference on Human Factors in Computing Systems, Monterey, CA.
Liljegren, E., (2006), Usability in a medical technology context assessment of methods for usability evaluation of medical equipment, International Journal of Industrial Ergonomics, vol. 36 (4), pp. 345-352.
Publisher – Google Scholar
Lindgaard, G. and Chattratichart, J. (2007). Usability testing: what have we overlooked? In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 1415-1424. ACM.
Publisher – Google Scholar
Manzari, L., and Trinidad-Christensen, J. (2013). User-centered design of a web site for library and information science students: Heuristic evaluation and usability testing. Information technology and libraries, 25(3), 163-169.
Publisher – Google Scholar
Molich, R., Ede, M., Kaasgaard, K. and Karyukin, B. (2004). Comparative usability evaluation. Behaviour & Information Technology, 23(1):65-74.
Publisher – Google Scholar
Nielsen, J. & Molich, R. (1990). Heuristic evaluation of user interfaces. Proceedings of the ACM CHI’90 Conference on Human Factors in Computing Systems, 249—256. New York: ACM.
Nielsen, J. (1994). Usability engineering. Morgan Kaufmann.
Nielsen, J. (2000). Why you only need to test with 5 users. Test 9 (September 23).
Nielsen, J. (2001). Success rate: The simplest usability metric, available at: [http://www.useit.com/alertbox/20010218.html], accessed on 11/6/2012
Nielsen, J. (2006). Quantitative studies: How many users to test. Alertbox, June, 26:2006.
Nielsen, J. (2009). Authentic behavior in user testing.
Nielsen, J. and Loranger, H. (2006), Prioritizing web usability, New Riders Press, Thousand Oaks, CA, USA.
Oztekin, A., Konga, Z., and Uysal, O. (2010). UseLearn: A novel checklist and usability evaluation method for eLearning systems by criticality metric analysis. International Journal of Industrial Ergonomics, 40(4): 455-469, 2010.
Publisher – Google Scholar
Rubin, J. and Chisnell, D. (2008). Handbook of Usability Testing: How to Plan, Design and Conduct Effective Tests. Wiley India Pvt. Ltd.
Sauro, J. and Kindlund, E. (2005). A method to standardize usability metrics into a single score. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 401-409. ACM.
Sears, A., (1997), Heuristic walkthroughs: Finding the problems without the noise, International Journal of Human-Computer Interaction, vol. 9 (3), pp. 213-234.
Publisher – Google Scholar
Tan, W., Liu, D. and Bishu, R. (2009). Web evaluation: Heuristic evaluation vs. user testing. International Journal of Industrial Ergonomics, 39(4): 621-627.
Publisher – Google Scholar
Tullis, T. and Albert, W. (2008). Measuring the User Experience: Collecting, Analyzing, and Presenting. Morgan Kaufmann, Burlington.
Tullis, T., Fleischman, S., McNulty, M., Cianchette, C. and Bergel, M. (2002). An empirical comparison of lab and remote usability testing of web sites. In Usability Professionals Association Conference. UPA.
Van den Haak, M., de Jong, M. and Schellens, P. (2004). Employing think-aloud protocols and constructive interaction to test the usability of online library catalogues: a methodological comparison. Interacting with computers, 16(6): 1153-1170.
Publisher – Google Scholar



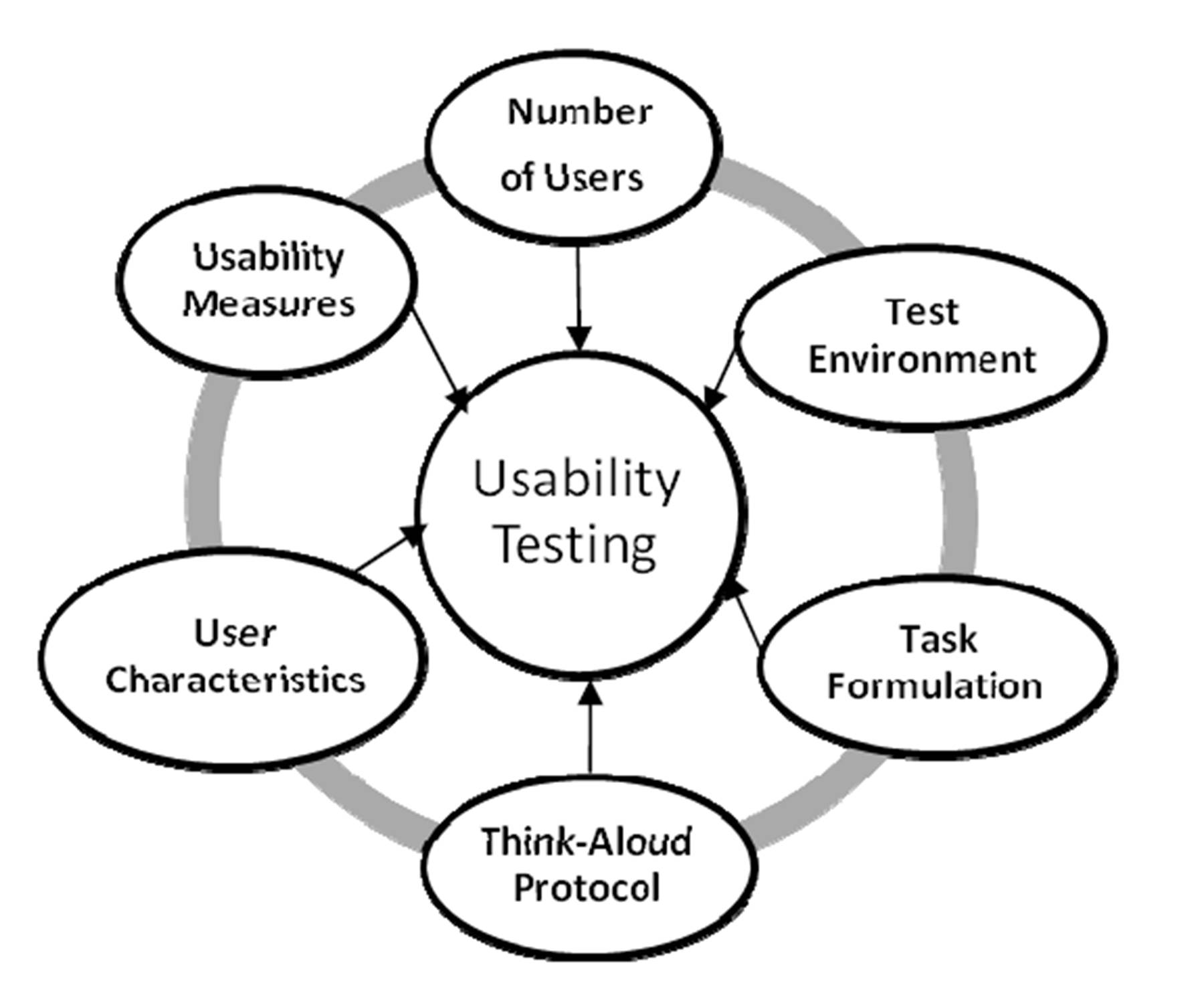

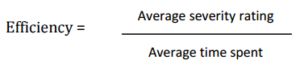 [Tan et al., 2009]
[Tan et al., 2009]  [Sears, 1997]
[Sears, 1997] [Sears, 1997]
[Sears, 1997] [Sears, 1997]
[Sears, 1997]