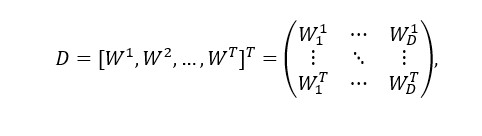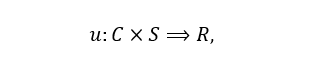Financial institution recommendation systems are being developed as big data applications. They solve specific problems; in particular, they give a clear idea of the available financial services for specific users, and participate in decision-making by financial intermediaries. However, the role and purpose of recommender systems are not limited to their technical and informational characteristics. They play an important role in the management strategy of financial intermediaries, as well as in the credit culture and financial behavior of netizens. Modern recommender systems can be described as an intelligent and experienced financial “manager” who is knowledgeable about the financial condition, needs and habits of clients. Based on this knowledge, the systems propose reasonable solutions, and the customer can follow them. This paper proposes a framework that provides an understanding of the key topics related to financial services recommendation modeling in terms of restructuring the management of financial intermediation and its communication channels with customers, as well as the development of information filtering in the financial intermediary-client system. Approaches to the definition of the utility function of recommendation systems of financial intermediaries are examined. Also, the document identifies some important open issues that require further study.
Keywords: Recommender Systems, Digital-Finance, Information Filtering, Financial Intermediation Management.
Introduction
Financial institution recommender systems are being developed as big data software applications. These applications belong to a class of technologies for personalized filtering of financial information. They solve specific problems; in particular, they give a clear idea of the available financial services for specific users, and participate in decision-making by financial intermediaries. However, the role and purpose of recommender systems are not limited to their technical characteristics. They play an important role in the management strategy of financial intermediaries as well as in the online financial culture and financial behavior of netizens. Modern recommender systems represent a rather complex machine learning technology in business (Kordik, 2018).
The financial world is on the cusp of a transition to algorithmic intelligent systems that form the backbone of digital financial systems. They provide collection, analysis, storage and management of data (Kannan et al., 2016) in the financial industry, as well as the interaction between financial intermediaries and their clients. For AI to work well and efficiently, financial institutions must first understand where and how they can add value, lower service costs, expand their customer base, and expand their range of financial products and services. Ultimately, it all boils down to creating conditions for recommender systems to have the utility for both the financial intermediary and the customers.
The modern practice of managing financial markets has developed in such a way that it is based on approaches to probabilistic calculus, based on which the monetary paradigm is built and trade is organized. Its highest example is high-frequency exchange trading. Rating agencies, banks, hedge funds, pension funds and insurance companies “work” in the same direction. Their analysts offer probabilistic scenarios for the development of financial markets that push and direct activity in specific channels. Thus, the use of probabilistic methods for managing financial markets at both the public and private levels largely sets the tone and shapes future financial markets (Klioutchnikov and Molchanova, 2017). Moreover, they form the basis of modern recommender systems.
Until recently, financial intermediaries worked in rather closed communities with a high level of personification of connections. Each banker personally knew his clients and could give them recommendations based on personal knowledge of his activities. Personal relationships meant that customers received excellent services and bankers could reap the benefits of brand loyalty as they understood their customers’ needs, preferences, and fully knew their budget, turnover, and prospects (Klioutchnikov and Molchanova, 2011).
Everything has changed in the 21st century. Financial intermediaries have benefited greatly from expanding their client base; however, personal contact with them was lost. Nevertheless, the key to the successful promotion of financial products and services has been depending on the knowledge of customers and the state of their affairs. In many ways, modern algorithms help to solve these problems, which are united under a common umbrella of recommender systems (Falk, 2019).
In general, the recommender mechanism implemented by financial institutions can be seen as a smart and experienced financial manager with a good understanding of the financial health of clients – their needs and habits, estimated income and expenses, for example, in connection with a vacation or purchase of a new car, teaching children, etc. Based on this knowledge, he can make smarter decisions and better recommendations that will benefit both a specific client (good advice) and the business itself (an increased likelihood of demand for loans from clients or additional receipts of money to bank accounts). The recommendation engine works with ever-growing datasets. Its purpose is to offer consumers products and services depending on the various circumstances and conditions set by the financial institution. Each new recommendation can be based on past loans and payments of a specific client, or it can be aggregated by age, gender, or social status of the client, or take into account the history of his search, as well as the location, demographic situation, shopping, etc. The idea is pretty simple. It is about narrowing down the range of options for a client to a few important options that he/she is more likely to use.
A financial institution’s recommender systems can have a different focus and function; they can be viewed from managerial, social, user, information and technological positions. There are various definitions of recommender systems. In some cases, for complex information environments, they are defined as a set of decision-making strategies (Rashid et al., 2002). The following definitions are widely used: tools that help users search for knowledge records based on the interests and preferences of users (Schafer et al., 1999); tools for interacting with large and complex information spaces (Burke et al., 2011); ways to expand the social process by using knowledge about others to make their own decisions (Resnik and Varian, 1997); a mechanism for solving problems of information overload of users (Agilar and Arslan, 2009); solving algorithmic problems of filtering information flow in a given direction and software applications that belong to the class of personalized information filtering technologies designed to support decision-making in a large information space (Zuva, 2012). At the 14th ACM (2020) Conference on Recommender Systems (RecSys), recommendations are defined as a particular form of information filtering, that exploits past behaviors and user similarities to generate a list of information items that is personally tailored to an end-user’s preferences. At the same time, there are no definitions that reflect the specifics of recommender systems in the financial environment.
The study of recommender systems in the financial sector, conducted in the article, includes a wide range of issues, from determining their place in the strategy of managing financial institutions and participating in the choice of financial services by end-users to examining filtering methods and approaches to developing recommendations and determining the utility function.
The article reveals the current state and prospects of recommender systems in the system of strategic management of financial organizations. Complex computational procedures are becoming the backbone of the management of financial institutions. Recommender systems are at the forefront of the bank-client system. They not only provide initial contacts with clients but also provide channels and computation for their ongoing maintenance. The article discusses the current state, the main directions of use, and the promising directions for the development of recommender systems.
The Formal Basis for Study and Related Work
There are many types of recommender systems. The literature on recommender systems is no less diverse in topics and coverage of problems. Resnick and Varian’s (1997) seminal paper describes a recommender system in which people provide recommendations as an input, which the system then aggregates and forwards to appropriate recipients, and a way to expand the social process by using knowledge about others to make own decisions.
For complex information environments, recommender systems are often defined as a set of decision-making strategies (Rashid et al., 2002). The following definitions are widely used: tools that help users search for knowledge records based on the interests and preferences of users (Schafer et al., 1999), tools for interacting with large and complex information spaces (Burke et al., 2011); a mechanism for solving problems of information overload of users (Agilar and Arslan, 2009); solving algorithmic problems of filtering information flow in a given direction and software applications that belong to the class of personalized information filtering technologies designed to support decision-making in a large information space (Zuva, 2012). The variety of definitions is largely due to the diversity of approaches, applications and tasks of recommendation systems.
Over the past decade and a half, there has been a significant increase in interest in the study of recommender systems. It has been catalyzed in part by the Netflix Awards (Bennett & Lanning, 2007) as well as the annual ACM Conferences on Recommender Systems. 14 ACM conferences on recommendation systems took place between 2007 and 2020. During this time, more than 400 thousand articles have been published on a variety of issues in the development and operation of recommender systems.
At the 14th ACM 2020 Conference on Recommender Systems, the following definition was given: “A recommendation is a special form of information filtering that uses past behavior and user similarities to create a list of information items that is personalized to the preferences of the end-user.”
Despite the extensive topics and versatile approaches that the conference participants considered, the issues of the functioning of recommendation systems in the financial sector and the requirements for them from financial institutions, as well as the specifics of filtering information when developing financial recommendations, did not interest the researchers.
Design/Approach
The preparation of each recommendation consists of three parts: entry, model and exit. The problem is solved in different ways. The article has selected promising areas of solutions.
The development of the idea took place in the following direction: the embedding of recommendation systems into the strategic management system of financial intermediaries → search engines (Salton and McGill, 1983) → text analysis systems (Miymoto, 1990) →filtering information flows (Palmgren et al., 1995) and texts (Palme et al., 1996) → text recognition systems (Karlgren and Cutting, 1994) and assessment of speech emotionality (Jannach et al., 2020) → information availability in complex systems (Fisher and Stevens, 1991) + level assessment interest for recommendations (Kargren, 1990) → recommender systems (Bobadilla et al., 2013; Isinkaye et al., 2015) → formalization (Adomavicius and Tuzhilin, 2005) and measurements of the utility of recommender systems (Jannach and Jugovac, 2019).
Recommender Systems in Financial Intermediaries’ Management Strategy
Recently, there has been a significant increase in the functionality of recommender systems in the financial sector. An additional impetus to their development was given by the pandemic caused by Covid-19. It contributed to a further reorientation of the population from offline to online relationships with banks and other financial institutions. Recommender systems are making an important contribution to the development of online finance. In modern conditions, they are an integral part of the strategy for managing financial intermediaries and are widely used by network users when choosing financial services. Recommender systems, on the one hand, are used to influence consumers and maintain their interest in financial services and products; on the other hand, they aim to help consumers choose the right service as well as provide financial services advice. Thus, netizens are constantly confronted with recommender systems. Modern recommender systems have become an important part of solving the problem of information reboot of the financial world towards the creation of an intelligent system for managing the digital financial content and web users.
Recommender systems of financial intermediaries are being embedded into social networks and the websites of retail operators. In social networks, they not only collect the necessary information but also get into an interactive dialogue with users of social networks. In commerce, they accompany the offer of goods and the choice of payment methods, including lending. Various ideas and techniques are applied to provide users with suggestions based on their specific needs and preferences as a result of collecting and analyzing huge databases, from filtering information, modeling user behavior, artificial intelligence, and predictions to enabling interactive features in the user interface and calculating probabilistic scripts. As a result, the functions of recommender systems are changing, their importance in the financial community is increasing, and the online services provided with their help are expanding.
Modern recommender systems provide additional preferences for initiators. If a financial intermediary is going to offer clients a new financial service or launch a new product on the financial market, he determines the consumer’s reaction to the new product; the costs associated with the choice; and the benefits to be gained from its implementation. This requires a reliable engine and supply chain, and the movement of new services. However, it is becoming increasingly difficult to carry out cost and profitability calculations at all the stages of promoting a new financial product and service in a changing market. Uncertainty has a chilling effect on the financial business. Many problems arise due to changes in consumer behavior, changes in government regulations, and possible new proposals from financial startups. In this regard, it is necessary to identify and recognize new problems, as well as to be able to solve them and customize new services and products following their requirements.
With the increasing use of deep learning, recommendation filters can “see” things differently than they did when initially setting up and tuning (training) systems for their solutions. They are good at recognizing problems and eliminating human prejudices. Separate recommendation filters allow you to see the entire process of recognizing problems and adapting to their solutions; others are a black box offering filtering results without explaining how they were obtained. The former is more suitable for analytical work, while the latter is more suitable for online customer service and marketplaces (for example, for high-speed stock trading).
There are many more boundaries and solutions. To a large extent, the speed of decision making and their reliability depend on various factors. They are based on both the internal structure of the financial institution and the external environment. In particular, a lot depends on the consumer – the frequency and form of his contacts with banks, financial condition, age composition, gender, social status, etc. The selected filter largely determines the performance and efficiency of customer contacts and the operation of the entire system.
From a technical point of view, recommender systems rely on algorithms that learn from existing data, generated by a supplemental data system and draw on previous experience, similar situations, and use a common knowledge base. From an organizational point of view, the driving force behind the introduction of recommender systems into the management system of financial intermediaries is their ability to be at the forefront of customer requests. Thus, they provide the necessary information, prepare, and propose operational solutions for the current and future management of a financial intermediary.
Recommender systems are involved in the preparation of management decisions by analytically processing information from the supply and demand side. On the demand side, they assess, first of all, the dissatisfaction/satisfaction of consumer demand for financial services, consumer preferences, and financial capabilities of clients. On the supply side, the most important factors for assessment may be the good availability of a wide range of data, on the one hand, for customers (which allows for more accurate and timely assessments of credit and insurance, and reduces the cost of the intermediary process), and on the other hand, about financial services that are convenient for customers and intermediaries.
Thus, the recommendation engine can be seen as an excellent tool for proper filtering: customers see only relevant data following their capabilities and preferences. This is why a good recommendation system must constantly learn and adapt to new users’ behaviors. Secondly, it must receive fresh data in real-time, which is achieved in the course of its work. But along with a good filtering tool, recommender systems have another important property. They are becoming one of the management tools and occupy an important place in the overall organizational structure of financial intermediaries.
So, recommendations serve, on the one hand, as an effective way to help Internet users cope with the problems of information overload, and on the other hand, in the promotion of financial services and products. They are becoming more and more important in business strategy and day-to-day management, and they largely determine the financial business model. Recommender systems are especially popular in the financial industry, where recommendations on the choice of services and products are often aimed at helping the client find the necessary loans with acceptable conditions, insurance policies, and buy/sell securities. These services can help both meet the needs of the client and increase the turnover and income of the financial intermediary. In general, recommender systems can be seen as a smart and experienced financial manager who is knowledgeable about the client’s financial condition, needs and habits. Based on this knowledge, the system can propose reasonable solutions, and the client can follow them. Usually, recommender systems are designed to support optimal decision-making. In this regard, they play an important role in the strategic management of companies. The financial industry is rapidly moving towards intelligent algorithmic systems that lay the foundation for future universal financial platforms and cash flow management.
Features of Recommender Systems
A side effect of the pandemic has been the acceleration of a pre-existing trend. Recommender systems allow Internet users to receive the necessary information about financial products and services remotely, and apply for loans and make payments via a smartphone. The pandemic has strengthened the case for the introduction of a digital transformation of the financial system, with the development of recommender systems and information filtering algorithms. Over the past 30 years, the recommender systems have been constantly improved, have taken over new areas, have been embedded in the organizational structure of financial institutions, and have become an integral part of many websites.
There are various reviews of the recommender system literature (e.g., Kumar, 2010; Zuva et al., 2012; Bobadilla et al., 2012; Horvath, T. and Carvalh, A. (2016); Wassif, 2017; Sohail et al., 2017; Sabeghi and Asghari, 2017; Jannach et al., 2020) that address general and specific questions about their development. There are quite a few research papers on e-commerce (e.g., Markellos et al., 2009; Chauhan et al., 2020; Bayer et al., 2020; Rahman et al., 2020). The financial sphere was of much less interest to researchers of recommender systems.
Financial institutions’ Recommender Systems use various sources of information to predict user behavior and provide them with service recommendations. T. Zuva et al. (2012) consider recommender systems as tools for filtering the information flow to search, select and calculate the probability level of events that indicate the behavior of the system, its parts and elements. Using this principle, financial institutions determine customer preferences and evaluate and value the financial services they recommend to customers. Recommender systems can operate in the face of the significant growth in the volume and diversity of data. They have established themselves in social media, e-commerce, and, more recently, in the financial industry. The integration of social networks with commercial and financial intermediaries increases the importance of these algorithms for analyzing random events and developing matrices of their occurrence with a probabilistic result that serves to rank supply and demand for financial services. The multipurpose nature of information filtering is suitable for finding clients for the provision of services for lending, payments, insurance, investment, and stock trading. This mechanism has entered the practice of online life insurance, lending, portfolio management and stock trading.
Based on the various methods used to calculate recommendations, it is customary to divide the existing systems of recommendations into three ((Isinkaye et al., 2015) or four main categories (Aggarwal, 2016), namely: collaborative filtering, content-based filtering, knowledge-based filtering and hybrid filtering.
Content filtering (Poudya, 2018; Das, 2015) is used when a client selects certain financial products and services, after which he can be recommended similar products and services (based on the similarity of the attributes of the analyzed elements – for example, repeated customer requests).
Collaborative filtering (Grover, 2017) can prepare recommendations for services related to basic services or additional services that can complement services (takes into account the preferences expressed by the user during the previous lending).
Knowledge-based filtering (Aggarwal, 2016) – a special type of recommender system that takes into account the range of financial products and services and customer preferences, and filters information within the established recommendation criteria.
Hybrid recommender systems (Bohme and Frank, 2017) – use two or more filtering approaches, combine the results and send them to recipients. The main methods of “linking” different approaches are the following: weighting, mixing, and switching functions, and combining, independent of the order. At different times or to solve certain problems, it is possible to switch according to the priority of one or another approach.
Filtering information can also be performed using various other approaches. Among them are the following main ones:
Demographic filtering (Pazzani, 1999) – filtering information based on demographic and social principles (ethnicity, gender, age, education, profession, income level, etc.).
Filtering based on utilities (Koteshov, 2018) (Utility-based model) allows clients to select services, tools and environments suitable for a particular client. Each action and each service is evaluated based on its usefulness to the user.
Target filtering (e.g., target model, target-based model, and target-based agent) further enhances model-based capabilities using information from the “target” (Kimbler et al., 1997). The target model describes the desired situations. It recommends ways to achieve goals. This approach orients the user towards several possibilities – scenarios that allow you to achieve the target state. Targeted filtering is more commonly used in stock portfolio management advice.
Filters Based on Deep Learning and Reinforcement Learning (Sewak, 2019) – provide a broader content coverage for items with low user interaction, based on the potential of advanced artificial intelligence.
Most financial institutions prefer fairly simple guidelines, using one or two types of filtering. Nevertheless, recently, according to J. Rocca et al. (2019), recommendation systems based on a variety of filters are increasingly being used.
Each financial intermediary has its requirements for recommendation systems. Therefore,, the technologies and approaches for recommender systems are quite different. Approaches range from statistical to ontological. An analysis of publications at the recent ACM conferences shows that the field of application of recommender systems has a strong influence on the approaches and methods that are used in recommender systems. Moreover, in different subject areas, the attitude of users toward the utility function of systems can vary – the value can be maximized or minimized, but it will never be neutral (zero) or negative.
When choosing the approach to recommender systems for a particular financial institution, it is always recommended to refer to the knowledge bases that underlie any recommender system. Moreover, as a source of knowledge, you can select one or several databases (for example, internal – data from financial institutions about customer transactions, and external – data from social networks). In the accepted classification, the knowledge is divided into three main types, according to its use (Felfernig and Burke, 2008): (i) social knowledge: about the user base as a whole, (ii) individual knowledge: about a specific user for whom recommendations are required (and, perhaps knowledge of the specific requirements that these guidelines should meet), and finally, (iii) knowledge of the content of the recommended elements: ranging from simple lists of functions to more complex ontological knowledge and knowledge of the means and purposes that enable the system to reason about how the product can meet the needs of the user.
The system can have one dataset as the main source of knowledge, and other datasets as auxiliary. In such cases, data from different systems can be weighted differently when filtering and developing recommendations. Some data may be explicit and others implicit. Therefore, it is important to classify both the databases and the data in them. Initially, the main approach was to assess all information (Bennet and Lanning, 2007). However, then other approaches began to be applied, which, in form, corresponded to the reasoning and gave in to the technique of mathematical approximation, which works exclusively based on assessments of both, social groups and individuals. In this regard, the problem of distribution of knowledge by priority arose. This problem can be solved, in particular, by the methods of game theory – Nash bargaining and competitive equilibrium with equal income (Branzei et al., 2017). This approach made it possible to determine a balanced state of knowledge and prioritize its use.
Filtering Text Data
Despite some advances in textual analysis, most of the existing recommender systems are currently focused on rating modeling (Ling et al., 2014). In most cases, the extensive information included in the text of the review was ignored, and industry specificity was not taken into account. However, the financial sphere involves taking into account broader and more diverse information for the preparation of recommendations. At the same time, much attention is paid to the context, which largely determines the general nature, attitude and focus of the client’s interests. Contextual information is often the basis for many recommendations.
Various Internet sites such as www.mouthshut.com, www.wallethub.com, etc., contain a huge amount of data about different banks and insurance agencies. Various algorithms are used to process them. At the same time, fairly simple techniques are used to process such volumes of data consisting of texts. For this, punctuation marks and words that are not relevant for assessing the consumer mood (for example, is, a, an, the, about, etc.) are removed, and words (W) that can characterize position (P) and mood (M) of the client from which the dictionary is built from the dataset (D) are used. Each reference to the dictionary is represented as a binary vector of size D with indexes i in the dictionary if this word is present in the observation (test). In general, all observations can be represented as a matrix:
where T is the number of observations (tests). Each row of the matrix displays an overview of the binary vector – . By means of the support networks vector method (Yaday, 2018) (a set of similar learning algorithms with a teacher), multiple classifications of words in each observation are carried out with a gradual decrease in empirical error.
As a result, the data set is streamlined. In general, this task is reduced to regression analysis, which ultimately determines the general mood and position of the client to a possible appeal toward a particular financial product. Two dictionaries can be compiled – one to characterize customer positions – P, the other – moods for a particular product – M. In this case, there will be two test matrices.
The next step is training classification algorithms. To do this, several machine learning algorithms are used. The sequential filtering of text information removes random words, and identifies, according to certain patterns, those that characterize consumer behavior. A similar approach can be applied to audio and visual information – voice intonation and vocabulary, as well as gestures, facial expressions, and eyes – can also represent important behavioral information.
Speech, audio, and visual recommender systems use slightly different approaches and support a wider set of interactions (Jannach et al., 2020). They are often used as aids and as a background to justify and support selected recommendations. The development of this direction is mainly associated with the significant progress in the field of natural language processing, the emergence of voice control of banking operations, and the wider use of chatbot technology (Siangchin and Samanchuen, 2019).
Thus, the determination of the probabilistic behavior of the client is reduced to the analysis of the text, audio and visual information. These calculations, along with the data collection mechanism, can act as the basis for predictive analytics of the financial market. They serve as the basis for forecasts of future or other unknown market events, including possible customer calls to a bank or an insurance company for an appropriate service. The defining functions of these algorithms are that they provide a predictive estimate of the probability for each case tested – each transaction, event and client. Also, the conclusions may affect the assessment of credit risk, the potential of mergers and acquisitions, the identification of fraud, the creditworthiness of a client, liquidity planning, and hacker attacks on a bank’s server (Fletcher, 2011; Grey, 2019; Bharadwaj, 2019).
The move to machine learning has a lot to do with processing a large amount and variety of data. Data Augmentation (Zoph et al., 2019) is a strategy that allows practitioners to significantly increase the variety of data available for training models without actually collecting new data. Data Augmentation techniques such as cropping, padding and flipping are commonly used to train large neural networks. However, most of the approaches used in training neural networks use only basic types of augmentation. Although neural network architectures have been deeply studied, less attention has been paid to detecting data augmentation that captures data invariants.
Machine-Learning Algorithms
At the predictive level, machine-learning algorithms are used when choosing random variables that fully determine the general movement or requirements of the recommender system. They increasingly begin to determine the direction of algorithmic development not only of recommendation systems but also of the entire strategy for managing financial intermediaries.
Each type of algorithm has its own peculiarity of working with random and fussy variables – it allows you to estimate the probability of occurrence of events in different circumstances, from different positions and in accordance with the requirements of the system, which is especially important with the growing volume and variety of data. Each type of system has its own strengths and weaknesses of probabilistic evaluations, and they are all suitable for evaluating random events in the financial markets. Typically, a set of algorithms allows you to extract patterns and hidden information from a huge database. Thus, the probability of events is calculated, and on its basis forecasts are made. For example, the Bayesian network is becoming a fundamental method for managing the uncertainty of complex systems. Thus, it becomes possible to go search for alternatives and conditional probabilities. This approach expands the possibilities of calculating the probabilities of events under various conditions (for example, when buying an apartment, obtaining mortgage loans for a country house with possible accompanying purchases and additional lending). Almost all recommender systems switch to using Bayesian methods of analysis due to the complexity of the tasks.
At the same time, neural networks serve to model the ability of the human brain to perform parallel processing, but they do not always explain predictions and reveal the big picture indicating the state of the system. However, actions based on the principle of entering the black box and receiving results from it are fully consistent with the interactive online system of communication with the client and the service for the constant processing of the results of such communication procedures.
In supervised learning scenarios, generative and discriminative classifiers are widely used. A generative classifier is based on statistical models that are used to study the underlying distribution of data according to their similarity/difference or based on user history. For this, the general distribution of the probability of the data P (X, Y) is fixed in a certain interval (between X and Y), and in the absence of boundaries, the probability p (X) is simply estimated. The discriminant method is based on fixing the conditional probability p (Y | X), which enhances its performance, especially when moving to bigger data (a lot of data) (Mitchell, 2005).
The statistical inference obtained with a generative classifier follows from the study of what is not directly observed, based on the observed data (Rocca, 2019). In other words, inferences are made based on some observable variables in a particular population or a sample of customer behavior data; that is, based on statistics, the inference is made from a Bayesian point of view. In this conclusion, the prior knowledge, modeled using the probability distribution, is updated when a new observation appears. Thus, the recommendations are constantly updated, which provides a link between a priori knowledge and the knowledge gained from observation (probabilistic data).
A Generative classifier allows you to study a recommendatory model that generates data, taking into account both the ways of their distribution and the probabilities, which allows you to move on to predicting the sequence of customer demand for financial services. The Discriminative model can distinguish between real data and draw boundaries between different needs (by examining the conditional probability distribution p (Y | X)), as well as compare the received recommendations with the real needs of the client. In particular, the combination of generative and discriminant filtering makes it possible to compare new recommendations with typical cases when a positive result was previously achieved, and on this basis form a generalized experience of previously solved problems (Shalman et al., 2019).
The interaction of the two methods (generative and discriminatory filtering) can be compared to traditional management, in which day-to-day management is combined with auditing. The difference lies in their almost simultaneous action, which increases not only the managerial response to inspections but also the responsiveness and adaptation to changes.
Data Augmentation Approach
Many financial models began to incorporate machine learning-based blocks, which allowed them to expand the practice of their application and “learn” to perceive and process large information flows with implicit, imprecise, and fuzzy data sets, as well as make recommendations on circumstances with insufficient information (Tran et al., 2017).
To solve this problem, a data augmentation technique is used. It can significantly increase the variety of data available for training models without actually collecting it. Various training methods are used to train large neural networks. However, most of the approaches used in training neural networks use only basic supplemental data (Ho et al., 2019), which limits the possibilities of this method to work with an incomplete dataset. A robust learning process for deep learning relies on large annotated datasets that are expensive to acquire, store and process. A reasonable alternative is the ability to automatically generate new samples (Liang and Liaw, 2018).
For this, algorithms that can adapt to changing circumstances are widely used. Generative models stand out among them. It is an area of machine learning related to the characterization of the P (X) distributions defined between data points X in some multidimensional space X (Doersch, 2016). For example, text or correspondence from web users or many web browsers is a natural set of data. In parallel, an artificial dataset is created in which each “data point” (word) can have different sizes. The task is to capture the relationship between different dimensions (meanings of words in this context) in the created model. For example, the connection of words has a general relationship and is organized to characterize the position of the user (correctly organized into objects). The generated model should “capture” these dependencies with some accuracy. Only then will the artificial model match the natural model, and the generated dataset will match the natural dataset. The better the model reflects the semantic meaning of the data, the more the artificial model data matches the natural data. In this case, the generative model P (X) calculates the distribution of data numerically, which allows the entire process to be reduced to the usual calculations and ratings.
Nevertheless, to determine the preferences of consumers and the transition to their rating, it is necessary to carry out not so much accurate modeling of the semantic meaning of texts, observed correspondence, and viewed web pages, to correctly assess the semantic load of various datasets and compare between them. If the model prefers X, it should have a high probability, while random desire refers to random noise and has a low probability. To determine the likelihood level, more examples that look like natural datasets are usually generated.
The technological perspective of adaptive models is to use deep learning techniques to train and estimate probability distributions between under-populated data types and prediction functions (Bengio, 2009). Among such models, a class of generative and discriminant models is distinguished (Chen et al., 2019). The organizational perspective of such financial recommendation models is to use the principles of competition between the two methods to obtain filtering data.
Checking and correcting the data and constantly comparing it with the observed data achieve the adequacy and reliability of the results. Competition, comparison and verification are carried out at all the stages of working with data. The organizational perspective of modeling financial recommendations using adaptive algorithms summarizes their management focus. A set of adaptive algorithms involves combining current actions with the constant verification of their results. Thus, a constant adjustment of relationships with clients and all financial activities is achieved, taking into account the external changes and internal goals of the institution. The relative simplicity of data input and output, as well as calculations, ensures high accuracy of results at high speed, which determines the computational perspective of such models. Moreover, the complexity of the algorithms and multilevel checks do not affect the response speed in any way.
Prospects for the application of generating adversarial networks in recommender systems of financial intermediaries
The first generative models were less in demand since they required complex probabilistic computations that arise when assessing maximum probability and associated strategies. However, Ian Goodfellow and colleagues (2014) at the Google Generative Adversarial Network (GAN) improved their filtering techniques in 2014, making the computation process much faster and easier. Initially, the innovations were related to working with images, but later they extended to text data and forecasting consumer behavior (Ahirwar, 2019). Using the GAN, they began to prioritize and rank various prediction scenarios and implemented an augmented reality (AR) system (ClodState, 2019). AR had significant prospects in forecasting consumer demand for loans due to a change in consumer position. Significant progress has also been made in discriminatory models. They were based on backpropagation and elimination algorithms with good gradient descent.
GANs can generate almost any dataset. Thus, it became possible to create artificial datasets that meet all the rules of “natural” datasets (Marr, 2019). This data can be used to train models as they create scripts according to customer preferences. Typically, discriminatory models complement generative ones (Zhang et al., 2018). If the latter generated new data, then the former not only checked it but also ranked it by the level of probability, comparing it with real data. Discriminator systems checked the data obtained by generative methods at each level.
Thus, the data obtained in each layer was corrected and tested taking into account the real data. As a result, the accuracy of the results obtained has increased. For this, two competing networks were involved; one generated new artificial data (generator), and the other compared it with real data (discriminator). Moreover, each network was trained in turn. Another feature of this approach was that the training was unsupervised since the combination of training and parallel learning processes allowed for the cross monitoring of these processes (Sendik, 2020). These networks had self-monitoring functions since the discriminator constantly monitored the correspondence of the generated data and compared it to reality.
The use of two approaches in recommender systems in the financial sector has significantly increased the performance and effectiveness of recommendations. The next step in improving these methods was the development of algorithms that are capable of recognizing text in conditions of strong noise, as well as highlighting, in a huge mass of data, non-essential data that directly affects the observed processes and objects. In particular, algorithms that allow you to remove the background when saving text content have appeared. Conditional generative adversarial networks (cGANs) have also solved this problem (Zoufal et al., 2019).
Text and audio data play an important role in identifying complex financial needs. Therefore, researchers turned to the development of algorithms that take into account the semantic features of texts (Murugesan et al., 2020). As a result, more reliable systems for recognizing hidden data have been created. In the second half of the last decade, algorithms that learned to recognize the styles and emotional coloring of texts were developed (Johnson et al., 2016). Such algorithms have been improved and trained using the vanilla GAN, which makes it possible to recognize and identify complex texts, as well as translate obscure styles into understandable and simple ones (Cheng et al., 2019; Jing et al., 2019).
However, the algorithms for generating vanilla have proven to be insufficiently reliable. They did not allow the sequential generation of sequential symbols from natural texts (Fang et al., 2019). They also did not give reliable results when restoring texts (Liu et al., 2018). Consequently, the vanilla GAN failed to generate not only crisp images but crisp texts as well (Chen et al., 2018). Because the financial sector needs accurate results, its widespread use in this area is limited.
Key challenges in identifying clients’ complex financial needs include identifying hidden and invisible data and relationships, and identifying hidden emotional and style expressions. Complex financial problems are often associated with invisible relationships and lack simple examples. Recent research has shown that modern generative networks can handle such tasks. They can be used to create reliable systems not only for generating missing data but also for identifying and recognizing hidden data. Generative adversarial networks allow connections between a text area and a knowledge graph. To do this, the generator is trained to first generate artificial data and relationships that reflect or look like natural data and relationships, and then embed them into datasets with noisy texts.
Despite common disadvantages, conventional algorithms can be used to overcome several generation disadvantages. For example, they are associated with improving the accuracy of the results due to (i) a clearer sequence in the use of discriminators to check the generation results (Zhang and Killoran, 2019), (ii) gaining more detailed control over the generation of sequential texts, and (iii) a more precise definition of the required properties in them.
Recently, there has been a lot of talk about quantum generative competitive deep learning systems (Dallaire-Demers, 2018; Du et al., 2020), which will allow new approaches to improve accuracy and speed up computations.
In such systems, the optimization between the two sides of the computing process – the complexity of scaling (laboriousness and slowness) and the enormous potential of quantum computing (speed and volume) – will become a major challenge. This problem is supposed to be solved using hybrid quantum-classical text generators (qGAN) (Zoufal et al., 2019). In these generators, the quantum component is responsible for the speed and amount of data, while the classical component is responsible for scaling.
The combination of generative techniques for working with discriminant data facilitates forecasting and developing recommendations. To do this, these processes are divided into two fairly simple processes – making forecasts and checking them. During an audit, comparing it with natural data validates simulated data; however, despite the simplicity of the calculations, the practical application of these two simple methods is extremely difficult.
Approaches to Measuring the Utility of Recommendations
The problems of formalizing recommendation systems are directly related to the issues of parameterization – measuring the performance and efficiency of the system both for the user and for the financial institution.
Research on recommender systems usually focuses on the utility of recommender systems to consumers in terms of reducing information overload. However, a new research is emerging that looks at the utility of recommender systems from a broader perspective (Jannach and Jugovac, 2019) including a long-term social impact (Madenov et al., 2020).
The definition of user effect can be approached using the following formalization of recommender systems, proposed in 2005 by G. Adomavicius and A. Tuzhilin (2005):
where C is the set of all users, S is the set of all non-negative elements (financial products and services) that can be recommended, U the utility function that measures the usefulness of the elements to the user c, and R is a fully ordered set (for example, non-negative integers or real numbers in a certain range that provide a ranked set of financial products or services). For each user c∈С, an element s∈S is selected which maximizes the user’s utility. Interactive interactions in the system are achieved with the help of personalized recommendations (McGinty and Reilly, 2011).
Some recommendation systems have a utility, not for each specific user, but a group of users and/or a group of financial products and services. In such cases, the utility is calculated for certain subsets – and .
For financial institutions, the utility is usually defined as maximizing utility in terms of business value, such as sales and profits (Jannach et al., 2016).
The proposed approach does not always correctly assess the real usefulness of the recommendation system for service providers (Jannach and Adomavicius, 2017), including financial institutions. One approach to increase the usefulness of the referral system to the financial intermediary is to include information targeting the fact that a network user will use the financial intermediary’s settlement system or take a microloan. Ultimately, referral systems allow you to expand your customer base and services.
In general, there are current and long-term, specifically oriented, and generalized-universal utility functions of recommender systems. Therefore, the utility is considered with adjustments to the fact that it can be the following: (i) an increase in payment turnover, issued loans, attracting funds and the number of customers, (ii) increasing loyalty and retaining customers, (iii) increasing the likelihood of a network user in using financial services institutions, (iv) increasing the volume of service to customers with unique and complex needs (moving to the “long tail” service) and (v) reducing service costs, and increasing revenue and profit.
A new area of research into the utility of recommender systems is to what extent recommender systems satisfy the needs of all their users (Deldjoo et al., 2019). To this end, Yashar Deldjoo et al. (2020) use the Generalized Cross-Entropy principle to measure fairness for all the sides of the recommender model. At the same time, different concepts of justice can be included in the model. This approach allows you to adjust the model to almost any request from both financial institutions and network users, as well as outside observers who find out the social effect of financial recommendations.
Discussion and Conclusion
The paper presents a set of methods aimed at describing, evaluating, and comparing recommender systems that are aimed at filtering and optimizing events according to certain criteria and predictive analytics for the financial system. Unlike most traditional approaches that use fairly simple ontological concepts of recommender systems or identify the mechanisms of their action and the specifics of certain algorithms and decisions, the proposed study shows the features of the action and purpose of recommender systems in the financial sphere with an overview of their main types, as well as the participation of recommender systems in the transformation of digital finance.
The rapid development of digital finance and the transition to online channels of communication with customers dramatically increases the number of contacts and users of services and products of financial institutions, which indicates the need for robotic algorithmic solutions. First, this article presents the reasons and conditions for the inclusion of recommendation systems in the strategic processes and management structures of financial intermediaries. Secondly, the role of texts in the preparation of recommendations is clarified, and methods of working with them when preparing recommendations for users of financial services are shown. Third, a number of recent studies that can serve as a promising guideline for the development of financial recommendations are presented and assessed. Fourth, the prospects for parameterizing the utility function of recommender systems and developing metrics for measuring the performance of recommender systems are considered.
Issues about the ability of recommender systems to contribute to the creation of added value for financial intermediaries and to improve the efficiency of financial services for clients require detailed analysis. In particular, metrics and utility functions provide the basis for quantifying performance for both financial intermediaries and their clients. Since metric techniques and results can be manipulated and abused, it becomes important to judge and evaluate recommender systems and filtering methods using universal metrics with a standardized set of data. The authors intend to investigate these issues in the future.
Financial intermediary recommendation systems deal with Internet users and various data on the web. The external network orientation of systems determines their functionality and place in the financial intermediary’s management system. Recommender systems allow financial intermediaries to better understand and respond to market demands faster, move on to individual advice, and provide round-the-clock customer service. A wide selection of filters and recommendation systems allows financial institutions to choose exactly those techniques that are more suitable for the specifics of their work and more fully suited to the digital financial business platform.
Of course, recommendation systems will evolve. On the surface, they might scare off non-technical marketers and financial managers, as they use fairly complex math and analytics to build and operate. However, this level of complexity does not affect the bottom line – most often all systems are used by financial professionals as a common means of promoting financial services. A new intermediary element is included in the system of relations between a client and a financial intermediary – a web-space with an algebraic filter and prepared algorithmic solutions that provide a more complete interaction between clients and financial institutions.
A possible option for the development of recommender systems could be the inclusion of general Internet mechanisms, universal knowledge, and databases in the orbit of recommender algorithms and computations. Deep learning leads to a focus on places where people, services, and products coexist, where they have broader and deeper relationships with each other than before, although this may not be entirely obvious. One of the possible options would be to connect the Internet of Things to the recommendation mechanism, which will significantly expand its functions. These issues also require additional special research.
The generally recognized unresolved problems of recommender systems are those related to a cold start, scalability (Ghazantar and Pragel-Benett, 2010), and ensuring reliable operation in conditions of insufficient and fuzzy information. Often, due to the limited choice, which is typical for many modern recommendation systems, customers refuse not only to use such systems but also from banking services, turning to alternative financial service providers. Therefore, in recent years, considerable attention has been paid to the issues of freedom of choice for the client. Personalization of offers according to user preferences prepares an idealized picture of the completeness of all the possibilities and a wide range of services. Modern recommender systems often limit perspectives and create an atmosphere of complacency. Recommendations can be overly personalized, which discourages users from considering non-standard solutions and prevents the discovery of new services and prospects.
In this regard, the question arises about the ability of recommendation systems to support the desire of users for new things, to motivate them to search, and to develop user initiatives. Offering ready-made solutions can disrupt the natural mechanism of selection, choice and decision. Therefore, the developers of recommendation systems are faced with the task of finding the optimal combination of advice and freedom of choice.
The authors believe that to study recommendation systems and their role in combining demand with the supply of financial services in the process of implementing the managerial functions of financial intermediaries, it is necessary to use (i) entropy as a measure of the probability distribution of supply and demand for financial services, (ii) chaos theory, using what can be considered as consumer behavior during cyclical and other fluctuations in conditions of increased uncertainty. Thus, with the transition to increased uncertainty and instability of supply and demand systems, especially in the context of a change in the phase of the cycle, the coordinates of the supply and demand systems of financial services also change, as well as the priorities between lending and savings, and so on. Similar changes occur during the pandemic and may occur during other disasters.
Recommender systems treat supply and demand systems as deterministic systems, albeit random and indefinite. The latter is especially true in the course of changes in consumer behavior and monetary policy. This shows the possibility of a detailed description of these systems and the connection of known and new algorithms to their analysis, as well as the necessary calculations. Generative and discriminatory filters make it possible to prepare recommendations even if the state of the system may differ greatly from its initial state, which is observed with each new login to the system (after discriminatory filtering). The recommendation system provides the ability to track all changes. The generative classifier determines the initial state of the system, while the discriminatory classifier specifies its state and corrects the system. Further, the interaction of the two filters allows you to take into account all the subsequent changes in an interactive mode – the client – the financial intermediary. The range of action of systems can be expanded to those limits that are determined by probabilistic values and are taken into account by indicators of information entropy.
In the system, entropy can act as an informational measure of the distribution of services in large databases. It can also testify and be a measure of their disorder/orderliness – the degree of disorder, which describes the degree of ordering (or disorder) of the system. Chaos can be used to describe randomness and unpredictability both in the choice of services and in matching demand with the supply of services.
A recommender system can be viewed as a system exhibiting complex dynamics, sensitive to initial conditions. User behavior and choices have a specific order. For example, the intensity of its oscillations obeys a powerful law of distribution. All services (supply), as well as the demand for them, tend to a Gaussian distribution. Filtering algorithms are tuned for a given distribution, which excludes accounting for demand in the “tails”. The main reasons why recommender systems use a Gaussian approach are: (i) ease of finding and responding to customers, (ii) averages provide a high level of likelihood that recommendations will meet demand, (iii) all types of supply and demand can be reduced to mean and deviation.
The connection of demand with the supply of financial services can be reduced to the key task that the recommender system solves. Combining two normal distributions – the distribution of the supply of services and the distribution of demand, solves the problem. The recommender systems are configured to reconcile the two distributions (a normal demand distribution and a financial service normal distribution). Gaussian distribution is associated with typical behavior, customer choice, and service distribution (on the supply and demand side). It can be used as a basis for rating services. Long tails can reflect the demand for complex and non-standard services that are ignored by modern recommender systems. It can be assumed that the ratio of supply and demand for financial services, reflected and focused in the recommendations, is the result of the interaction of the system’s ordered properties and its entropy.
The paper shows that the combination of generative and discriminant algorithms allows transforming the problem of finding and providing services in a fictional system, which, in its probability, approaches the real system of supply and demand. Such capabilities of the system allow you to simulate supply and demand and bring them to the maximum probability of real demand and supply. The paper shows that cross-validation helps ensure the correctness of the model. In the future, the authors intend to use a Bayesian approach to reconcile models and real data. Finally, since hybrid models based on generative and discriminatory filters can help improve interpretability and make predictive demand modeling more visual, these issues should be given more attention in the future.
From a technological point of view, recommender systems are based on information flow filtering to search, select and calculate the level of probability of events. This approach characterizes the behavior of the system and its specific parts and elements, in particular, customer preferences. It is also suitable for ranking events. From a managerial position, recommendation systems are part of the strategic management system of banks, insurance companies, etc. From the social side, their purpose is reduced to helping consumers in choosing goods and services. From an information point of view, recommender systems are an important tool for communication and information dissemination. From a psychological point of view, they are aimed at solving problems associated with information overload, possible stresses that arise with an increased amount of information. Thus, recommender systems have increased versatility; they have interdisciplinary relevance. As a result, they occupy a special place in the structure of modern society and require an integrated approach to their study.
References
14th ACM (2020), Conference on Recommender Systems, [Online], [Retrieved September 09, 2020], https://recsys.acm.org/recsys20/
Acilar, AM. and Arslan, A. (2009), ‘A collaborative filtering method based on Artificial Immune Network,’ Expert Systems with Applications, 36 (4), 8324-8332.
Adomavicius, G. and Tuzhilin, A. (2005), ‘Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions,’ IEEE Transactions on Knowledge and Data Engineering, 17 (6), 734-49.
Afridi, AH. (2019), ‘Transparency for Beyond-Accuracy Experiences: A Novel User Interface for Recommender Systems,’ Procedia Computer Science, 151, 335-344.
Aggarwal, CC. (2016), Recommender Systems: The Textbook, Springer, Yorktown Heights, New York, 498.
Ahirwar, K. (2019), ‘The Rise of Generative Adversarial Networks,’ Medium, Mar 28, 2019, [Online], [Retrieved September 09, 2020], https://blog.usejournal.com/the-rise-of-generative-adversarial-networks-be52d424e517
Bayer, S., Gimpel, H. and Rau, D. (2020), ‘IoT-commerce – opportunities for customers through an affordance lens,’ Electronic Markets, March.
Bengio, Y. (2009), ‘Learning deep architectures for AI,’ Foundations and Trends in Machine Learning, 2(1), 1-127.
Berkovsky, S., Taib, R. and Conway, D. (2017). ‘How to Recommend? User Trust Factors in Movie Recommender Systems,’ [IUI2017] Proceedings 22nd Int. Conf. Intell. User Interfaces Community, ISBN: 978-1-4503-4348-0,March 16-20, 2017, Limassol, Cyprus. 287-300.
Bharadwaj, R. (2019), ‘Predictive Analytics in Finance – Current Applications and Trends,’ Emerj, [Online], [Retrieved August 26, 2019], https://emerj.com/ai-sector-overviews/predictive-analytics-in-finance/.
Bobadilla, J., Ortega, F., Hernando, A. and Gutiérrez A. (2013), ‘Recommender systems survey,’ Knowledge-Based Systems, 46, 109-132.
Bohme, TJ. and Frank, B. (2017), Hybrid Systems, Optimal Control and Hybrid Vehicles: Theory, Methods and Applications, Springer.
Branzei, S., Gkatzelis, V. and Menta, R. (2017), ‘Nash Social Welfare Approximation for Strategic Agents,’ arXiv: 1607.01569v3 [cs.GT] 12 May 2017, 1-31.
Burke, R. (2002), ‘Hybrid Recommender Systems: Survey and Experiments,’ User Modeling and User-Adapted Interaction, 12 (4), 331-370.
Burke, R., Felferning, A. and Goker, MH. (2011), ‘Recommender Systems: An Overview,’ AI Magazine, 32, 13-18.
Cano, E. and Beel, J. (2017), ‘Hybrid Recommender Systems: A Systematic Literature Review,’ Intelligent Data Analysis, 21 (6), 1487-1524.
Chen, X., Li S., Li, H., Jiang, S. and Song, L. (2019), ‘Generative Adversarial User Model for Reinforcement Learning Based Recommendation System,’ Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, PMLR 97, 2019, 1052-61.
ClodState, (2019), ‘Generative Adversarial Networks and Creating Reality With AI,’ Medium, Oct 1, 2019, [Online], [Retrieved September 09, 2020], https://medium.com/better-programming/generative-adversarial-networks-creating-reality-with-ai-59fbb5b113c0
Dallaire-Demers, P-L. and Killoran, N. (2018), ‘Quantum generative adversarial networks,’ arXiv:1804.08641v2 [quant-ph] 30 Apr 2018, 1-10.
Das, S. (2015), ‘Beginner Guide to learn about Content Based Recommender Engines,’ Analytics Vidhya, [Online], [Retrieved August 26, 2019], https://www.analyticsvidhya.com/blog/2015/08/beginners-guide-learn-content-based-recommender-systems/.
Deldjoo, Y., Anelli, VW., Zamani, H., Bellogin, A. and Noia, TD. (2020), ‘A Flexible Framework for Evaluating User and Item Fairness in Recommender Systems,’ User Modeling and User-Adapted Interaction, July 2020, 1-47.
Deldjoo, Y., Anelli, VW., Zamani, H. Bellogin, A. and Noia, TD. (2019), ‘Recommender Systems Fairness Evaluation via Generalized Cross Entropy,’ arXiv:1908.06708v1 [cs.IR] 19 Aug 2019, 1-7.
Doersch, C. (2016), ‘Tutorial on Vibrational Autoencoders,’ arXiv:1606.05908v2 [stat.ML] 13 Aug 2016.
Du, Y, Hsieh, M. and Liu, N-n. (2020), ‘Quantum noise protects quantum classifiers against adversaries,’ arXiv:2003.09416v1 [quant-ph] 20 Mar 2020, 1-16.
Falk, K. (2019), Practical Recommender Systems, Manning Publications, 1-432.
Fang, S., Xie H., Chen, J., Then, J, Zhang, Y. (2019),‘Learning to Draw Text in Natural Images with Conditional Adversarial Networks, InProceedings of the Twenty-Eighth International Joint Conferences on Artificial Intelligence (IJCAI-19), Maccao, 10-16 August 2019, 715-722, ISBN (Online): 978-0-9992411-4-1.
Fisher, D. and Stevens, C. (1991), ‘Information access in complex, poorly structured information spaces,’ Conference on Human Factors in Computing Systems, CHI ‘91 Conference Proceedings, ISBN: 0-89791-383-3, April 27 – May 2, 1991, New Orleans, Louisiana, 63-70.
Felfernig, A. and Burke, R. (2008), ‘Constraint-based recommender systems: technologies and research issues,’ Proceedings of the 10th International Conference on Electronic Commerce (ICEC ’08), ACM, New York, NY.
Fletcher, H. (2011), ‘The 7 Best Uses for Predictive Analytics in Multichannel Marketing,’ Target Marketing, [Online], [Retrieved August 26, 2019], https://www.targetmarketingmag.com/article/7-best-uses-predictive-analytics-modeling-multichannel-marketing/.
Chauhal, G., Mishra, DV., Begam, MF. and Akhilaa, (2020), ‘Customer-Aware Recommender system for Push Notifications in an e-commerce Environment,’ IEEE Xplore, 03 February, ID 19319476.
Ghazantar, MA, and Pragel-Benett A. (2010), ‘A scalable accurate hybrid recommender system,’ The 3rd International conference on knowledge discovery and data mining (WKDD 2010), ISBN 978-0-7695-3923-2, 9-10 January 2010, Phuket, Thailand, 90-98.
Gielis, GA., Tzanavari ,A. and Papadopoulos, GA. (2014), ‘A Review of Recommender Systems: Types Techniques and Applications,’ In Encyclopedia of Information Science and Technology, Elsevier, 329-339.
Goodfellow, IJ., Pouget-Abadie, J., Mirza, M., Courville, A.,Ozair, S., Ward-Farley, D. and Bengio, Y. (2014), ‘General Adversarial Networks,’ org > stat > arXiv:1406.2661.
Grey, P. (2019), ‘Big Data Predictive Analytics In Financial Services,’ Cloud Computers, [Online], [Retrieved August 26, 2019], https://cloudcomputers.fun/big-data-predictive-analytics-in-financial-services/.
Grover, P. (2017), ‘Various Implementations of Collaborative Filtering,’ Medium, [Online], [Retrieved August 26, 2019], https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0.
Ho, D., Liang E. and Liaw, R. (2019), ‘1000x Faster Data Augmentation,’ Berkeley Artificial Intelligence Research, [Online], [Retrieved August 26, 2019], https://bair.berkeley.edu/blog/2019/06/07/data_aug/.
Horvath, T. and Carvalh, A. (2016), ‘Evolutionary Computing in Recommender System: A Review of Recent Research,’ Natural Computing, 1-22.
Isinkaye, FO., Folajimi. YO. and Ojokoh, BA. (2015), ‘Recommendation systems: Principles, methods and evaluation,’ Egyptian Informatics Journal, 16 (3), 261-273.
Jing ,Y., Yang, Y., Feng ,Z., Ye, J, Yu, Y., Song, M. (2019), ‘Neural Style Transfer: A Review,’ IEEE transactions on visualization and computer graphics (TVCG).
Jannach, D., Manzoor, A., Cai, W and Chen, l. (2020). ‘A Servey on Conversational Recommender Systems,’ rXiv:2004.00646v1 [cs.HC] 1 Apr 2020, 1-35.
Jannach, D. and Adamavicius, G. (2017), ‘Price and Profit Awareness in Recommender Systems,’ arXiv:1707.08029v1 [cs.IR] 25 Jul 2017, 1-5.
Jannach, D. and Jugovac, M. (2019), ‘Measuring the Business Values of Recommender Systems,’ ACM Transactions on Management Information Systems, 10 (4), 1-23.
Jannach, D., Resnick, P., Tuzhilin, A. and Zanker, M. (2016), ‘Recommender systems – beyond matrix completion,’ Communication ACM, 59(11), 94–102.
Johnson, J, Alahi A, Fei-Fei, L (2016), Perceptual losses for real-time style transfer and super-resolution, In European conference on computer vision (ECCV), Stanford University, Palo Alto, United States, 694–711.
Kannan ,S., Karuppusamy, S., Nedunchezhian, A., Venkateshan, P., Wang, P., Bojja, N., Kejariwal, A. (2016), Big Data Analytics for Social Media, In Big Data: Principle and Paradigms, Chapter 3, Elsevier, 2016, 63-94.
Karlgren, J. (1990), An Algebra for Recommendations. Syslab Working Paper 179, Department of Computer and System Sciences, Stockholm University, Stockholm, Sweden.
Karlgren, J. and Cutting, D. (1994), ‘Recognizing Text Genres with Simple Metrics Using Discriminant Analysis,’ arXiv:cmp-lg/9410008.
Kimbler, K., Johansson, N. and Slottner, J. (1997), ‘Goal-based filtering of service interactions,’ International Conference on Intelligence in Services and Networks, Fourth Intelligence in Services and Networks: Technology for Cooperative Competition, ASIN:B0108CO7SA, May 27-29, 1997, Cernobbio, Italy, Proceedings, Editors Al Mullery, Michel Besson, Mario Campolargo, Roberta Gobbi and Rick Reed, Springer, Berlin, Heidelberg, 97-106.
Klioutchnikov, IK. and Molchanova, OA. (2017), Finance: Development Scenarios, Moscow, Yurayt, 2017, 206, ISBN: 978-5-9916-8768-3.
Klioutchnikov, IK. and Molchanova, OA. (2011), Credit culture: essence, patterns, forms, Textbook, St. Petersburg, St. Petersburg Economic University Publishing House, 1-221, ISBN: 978-5-7310-2669-7
Knijnenburg, BP., Willemsen, MC., Gantner, Z., Soncu, H. and Newell, C. (2012), ‘Explaining the user experience of recommender systems,’ User Modeling and User-Adapted Interaction, 22, 4-5 (2012), 441–504.
Kordik, P. (2018), ‘Machine Learning for Recommender systems – Part 1 (algorithms, evaluation and cold start),’ Medium, Jun3.
Koteshov, D. (2018), ‘AI in marketing: The power of recommendation engines,’ eliNext, [Online], [Retrieved August 26, 2019], https://www.elinext.com/solutions/ai/trends/ai-in-marketing-the-power-of-recommendation-engines/.
Kumar, S. (2010), ‘R Recommender Systems,’ In Encyclopedia of Machine Learning, Chapter 338, Springer, 122-4.
Leskovec, J, Rajarman, A and Ullman, J. (2014), Mining of Massive Datasets, The 3rd edition, Stanford University Press, Stanford, 307-342
Liang, E. and Liaw, R., (2018), ‘Scaling Multi-Agent Reinforcement Learning,’ Berkeley Artificial Intelligence Research, [Online], [Retrieved August 26, 2019], https://bair.berkeley.edu/blog/2018/12/12/rllib/.
Ling, G., Lyu, MR. and King, I. (2014), ‘Rating meet reviews, a combined approach to recommend,’ Proceedings of the 8th ACM Conference on Recommender systems (RecSys ’14), October 2014, 105–112.
Liu, Y, Wang Z, Jin, H. and Wassell, I. (2018), Synthetically supervised feature learning for scene text recognition, In European conference on computer vision (ECCV), Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 11209 LNCS, 449-465.
Madenov, M. (2020), ‘Optimizing Long-term Social Welfare in Recommender Systems: A Constrained Matching Approach,’ arXiv:2008.00104v2 [cs.LG] 18 Aug 2020, 1-23.
Markellos, K., Markellou, P., Mertis, A. and Panayiotaki, A. (2009), E-Commerce Recommender Systems, In Encyclopedia of Information Communication Technology, Chapter 24, IGI Global, 180-8.
McGinty, L. and Reilly, J. (2011), On the Evolution of Critiquing Recommenders. In Recommender Systems Handbook, Ricci, Rokach, Shapira and Kantor (eds.), Springer, 419-53.
Mitchell, T. (2005), ‘Generative and discriminative classifiers: naïve Bayes and logistic regression,’ Semantic Scholar, 2005, ID 4822346.
Miyamoto, S. (1990), Fuzzy Sets in Information Retrieval and Cluster Analysis, Kluwer Academic Publishers, Dordrecht, Boston, 259.
Mouzhi, G, Delgado-Battenfeld, C. and Jannach, D. (2010), ‘Beyond accuracy: evaluating recommender systems by coverage and serendipity’ Proceedings of the 4th ACM conference on Recommender systems – RecSys ’10, ISBN: 978-1-60558-906-0, September 26-30, 2010, Barcelona, Spain, 257–260.
Murugesan, B., Sarveswaran, K., Raghavan, V., Shankaranarayana, SM., Ram, K. and Sivaprakasam, M. (2020), ‘A context based deep learning approach for unbalanced medical image segmentation,’ arXiv:2001.02387v1 [eess.IV] 8 Jan 2020.
Palme, J., Karlgren, J. and Pargman, D. (1996), ‘Issues when designing filters in messaging systems,’ Computer Communications, 19 (2), 95-101.
Palmgren, O., Karlgren, J. and Pargman, D. (1995), ‘GHOSTS – a filter for information streams,’ [Online], [Retrieved August 26, 2019], http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.47.4013&rep=rep1&type=pdf.
Pazzani, MJ. (1999), ‘A Framework for Collaborative, Content-Based and Demographic Filtering,’ Artificial Intelligence Review, 13, 393-408.
Poudya, R. (2018), ‘Content Based Filtering in Recommendation Systems,’ Medium, [Online], [Retrieved August 26, 2019], https://medium.com/@rabinpoudyal1995/content-based-filtering-in-recommendation-systems-8397a52025f0
Raghuwanshi, SK. and Pateriya, RK. (2019), ‘Recommendation Systems: Techniques, Challenges, Application, and Evaluation,’ In Soft Computing for Problem Solving. Advances in Intelligent Systems and Computing, Bansal J., Das K., Nagar A., Deep K., Ojha A. (eds.), vol. 817, Springer, Singapore. [Online], [Retrieved September 09, 2020], https://doi.org/10.1007/978-981-13-1595-4_12
Rahman, MM., Zaki, ZM., Alwi, NHBM. and Islam, MM. (2020), ‘A Conceptual Model for the E-Commerce Application Recommendation Framework using Exploratory Search,’ Journal of Computer Science, 16(8), 1163-71.
Rashid, AM, Albert, I., Cosley, D., Lam, SK, McNee, SM, Konstan, JA. and Riedl, J. (2002), ‘Getting to know you: learning new user preferences in recommender systems’ Proceedings of the international conference on intelligent user interfaces, ISBN: 1-58113-894-6, January 13-16, 2002 San Francisco, California, USA, 127–34.
Resnick, P. and Varian, HR. (1997), ‘Recommender systems,’ Communications of the ACM, 40 (3), 56-8.
Rocca, BG. (2019), ‘Introduction to recommender systems,’ Medium, Jun 3, [Online], [Retrieved September 09, 2020], https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada
Sabeghi, M. and Asghari, SA. (2017), ‘Recommender Systems Based on Evolutionary Computing: A Survey,’ Journal of Software Engineering and Applications, 10(5), 407-421.
Salton, G. and McGill, M. (1983), Introduction to Modern Information Retrieval, McGraw-Hill, New York, 448.
Schafer, JB, Konstan, J. and Riedl J. (1999), ‘Recommender system in e-commerce,’ Proceedings of the 1st ACM conference on electronic commerce, ISBN: 1-58113-176-3, November 03-05, 1999, Denver, Colorado, USA, 158–66.
Sendik, O., Lischinski, D. and Cohen-Or, D. (2020), ‘Unsupervised K-modal Styled Content Generation,’ arXiv:2001.03640v1 [cs.GR] 10 Jan 2020.
Sewak, M. (2019), Deep Reinforcement Learning. Springer, 1-203.
Shalom, OS., Uziel, G. and Kantor, AA. (2019), ‘Generative Model for Review-Based Recommendations, ‘DEBS ’19: Proceedings of the 13th ACM International Conference on Distributed and Event-based Systems, June 24 – 28, 2019 ACM New York, NY, ISBN: 978-1-4503-6794-3
Chen, F., Xiao G. and Chen C. (2019), An Attention-based Sequence Learning Model for Scene Text Recognition with Text Correction, In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, ACM, December 2019, Normal IL, USA, ISBN: 978-1-4503-7627-3, 215-220.
Siangchin, N. and Samanchuen, T. (2019), ‘Chatbot Implementation for ICD-10 Recommendation System,’ Conference: 22-24 August 2019 International Conference on Engineering, Science, and Industrial Applications (ACESI), Tokyo, August 2019,
Sohail, SS., Siddiqui, J. and Ali, R. (2017), ‘Classifications of Recommender Systems: A review,’ Journal of Engineering Science and Technology Review, 10 (4), 132-53.
Symeonidis, P., Nanopoulos, A. and Manolopoulos, Y. (2009), ‘MoviExplain: A Recommender System with Explanations,’ Proceedings of the Third ACM Conference on Recommender Systems, RecSys ’09, ISBN: 978-1-60558-435-5, 22-25 October 2009, New York, USA, 317-20.
Tran, T., Pham, T., Garneiro , C., Palmer L. and Reid I. (2017), ‘A Bayesian Data Augmentation Approach for Learning Deep Models,’ org > aerXiv:1710.10564v1.
Wassif, K. (2017), ‘Classifications of Recommender Systems – A review,’ Journal of Engineering Science and Technology Review, 10(4), 123-153.
Wilkinson, D., Sivakumar S., Sinha P. and Knijnenburg, DP. (2018), ‘Testing a Recommender System for Self-Actualization,’ [Online], [Retrieved August 26, 2019], http://sites.unica.it/enchires/files/2017/07/Enchires_Wilkinson_Sivakumar_Sinha_Knijnenburg.pdf
Yadav, A. (2018), ‘Support Vector Machines (SVM),’ Medium, [Online], [Retrieved August 26, 2019], https://towardsdatascience.com/support-vector-machines-svm-c9ef22815589
Zhang, Z., Liu, S., Li, M., Zhou, M., and Chen, E. (2018), ‘Bidirectional Generative Adversarial Networks for Neural Machine Translation,’ In: Proceedings of the 22nd Conference on Computational Natural Language Learning (CoNLL 2018), Brussels, Belgium, October 31 – November 1, 2018.190–199.
Zoph, B., Cubuk ,ED., Ghiasi, G., Lin, T-L., Shlens, J. and Le, Q.V. (2019), ‘Learning Data Augmentation Strategies for Object Detection,’ arXiv:1906.11172v1 [cs.CV] 26 Jun 2019, 1-13.
Zoufal, C., Luchi, A. and Woerner, S. (2019), ‘Quantum Generative Adversarial Networks for learning and loading random distributions,’ Quantum Information, 5, Article 103.
Zuva T., Ojo SO., Ngwira S.M. and Zuva K. (2012), ‘A Survey of Recommender Systems Techniques, Challenges and Evaluation Metrics,’ International Journal of Emerging Technology and Advanced Engineering, 2 (11), 382-6.