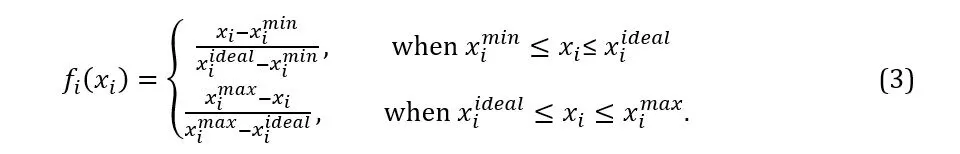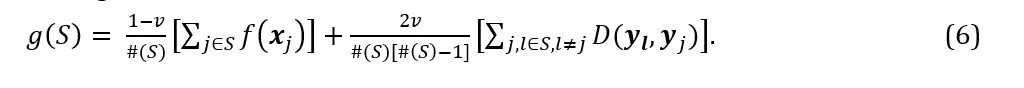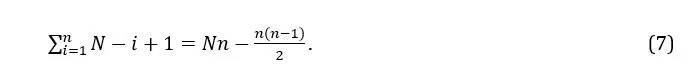Aleksander MARIAŃSKI1, Michał KĘDZIORA2, David RAMSEY3and Leopold SZCZUROWSKI4
1,2Department of Applied Informatics, Wrocław University of Science and Technology, Wrocław, Poland,
3,4Department of Operations Research and Business Intelligence,Wrocław University of Science and Technology, Wrocław, Poland
Volume 2021,
Article ID 367917,
Journal of Marketing Research and Case Studies,
12 pages,
DOI: 10.5171/2021.367917
Received date: 17 April 2020; Accepted date: 20 July 2021; Published date: 9 July 2021
Academic Editor: Dario Šebalj
Cite this Article as:
Aleksander MARIAŃSKI, Michał KĘDZIORA, David RAMSEY and Leopold SZCZUROWSKI (2021), “A Heuristic Method of Constructing Shortlists of Attractive Offers ", Journal of Marketing Research and Case Studies, Vol. 2021 (2021), Article ID 367917, DOI: 10.5171/2021.367917
Thanks to the Internet, consumers can easily obtain basic information about a very large number of offers at very little cost. This enables consumers to judge whether an offer of a unique valuable good (such as a flat or second-hand car) is potentially attractive, but more information (normally gained by observing an offer in real life) is needed to make a final decision. Automating the construction of an initial shortlist based on online information can be a useful heuristic approach to ultimately selecting an appropriate offer, while reducing search costs. The authors present an algorithm that constructs shortlists of attractive offers based on consumers’ stated preferences. The number of offers to be placed on the shortlist is given by the user. Such a shortlist can be interpreted as a list of offers to be physically viewed or as the first step in choosing such a set.
Keywords: Shortlist, Limited Rationality, Heuristic Decision Rule, Online and Offline Search, Multi-Criterion Decision Making
Introduction
The Internet allows consumers to find information about a wide range of offers at very little cost. However, due to the limited capacity of humans to process information, this can lead to the paradox of choice (Schwartz, 2004), which states that when there is a large set of offers, a consumer should concentrate on a small subset. In this way, a decision maker (DM) might not purchase the best offer, but this loss is compensated for, since less time and effort are required to make a purchase. Due to their limited rationality, consumers often use heuristics that are adapted to the structure of the problem faced (Simon, 1956: 129; Todd and Gigerenzer, 2000: 727-741).
A shortlist is adapted to situations in which a consumer can gain some information about offers at low cost, but the information required to make an accurate appraisal of an offer’s value is relatively costly.
This article considers the use of shortlists when the goal is to acquire a single valuable resource, rather than as a means to choosing several options. For example, Durbach and Davis (2012: 99-116) consider the problem of choosing several ways of reducing electricity bills. On the other hand, Belton (1985: 265-274) considers how a final choice is made after a shortlist has been constructed.
Much work has been recently published on the concept of shortlists (Masatlioglu et al, 2012: 2183-2205; Lleras et al, 2017: 70-85). Borah and Kops (2019: 401-420) consider search processes where DMs construct shortlists using information obtained from peers. The shortlist heuristic is also useful when offers are categorizable (Armouti-Hansen and Kops, 2018: 507-524) or multiple criteria are considered (Dulleck et al, 2011: 395-408).
Manzini and Mariotti (2007: 1824-1839) consider a model where shortlists of offers of ever decreasing size are constructed using a sequence of criteria until a final choice is made. Au and Kawai (2011: 608-614) consider a similar model where a shortlist of offers is constructed using initial information and then an offer is chosen from this shortlist based on a richer set of information.
Although the two papers described above describe the properties of such decision rules, little work has been devoted to optimization models involving shortlists. Ramsey (2019: 75-92) presents a model in which a DM uses a shortlist as a means to making a final decision. The DM cannot precisely measure the value of offers, but can rank offers according to the information currently available. Basic information about offers can be obtained at little cost. However, gaining more precise information about the value of an offer is much more costly. The strategy of the DM is defined by the length of the shortlist, k. The k most attractive offers according to initial information are inspected more closely, after which the best offer on the shortlist is accepted. When the search costs are convex in k, the optimal length of the shortlist is the smallest value of k satisfying the following condition: the marginal costs from increasing k (the increase in the search costs from increasing the length of the shortlist from k to k + 1) exceed the marginal gain from increasing k (the increase in the expected value of the offer accepted by increasing the length of the shortlist from k to k + 1). Olkin and Stephens (1993: 477-486) consider the problem of selecting a shortlist of candidates for a job when the goal is to employ the best of all the candidates available.
The model presented here addresses some shortcomings of the model of Ramsey (2019: 75-92). Firstly, that model does not explicitly consider the fact that decisions are made at each stage on the basis of multiple traits. Secondly, the value of a shortlist in exploring the range of the offers available is not considered. Various approaches to multiple-criteria decision making can be applied. For example, the TOPSIS approach (Technique for Order of Preference by Similarity to Ideal Solution, see Yoon and Hwang, 1995) measures the attractiveness of an offer according to its distance from the ideal offer in a multi-dimensional space defined by an offer’s traits. Górecka et al (2016: 1097-1136) present the MARS approach (Measuring Attractiveness around Reference Solutions), which may be interpreted as a generalization of the TOPSIS approach. This paper illustrates the algorithm based on the relatively simple SAW approach (Simple Additive Weights). The overall attractiveness of an offer is measured as the weighted sum of scores according to individual traits. Such a score is either a linear or triangular function of a trait. Kaliszewski and Podkopaev (2016: 155-161) argue that decisions made using more complex approaches can be interpreted as choices made using the SAW approach for appropriately defined weights.
The method is illustrated on the basis of the problem of purchasing a flat from a large database of offers. Figure 1 illustrates a non-automated search process based on forming a shortlist.
Given the potentially large size of a database holding quantitative information, the automated construction of a shortlist is of potentially great use to those searching for a flat. The DM must input the minimum, maximum and ideal values of the traits of interest, together with the relative importance of each trait and the required length of the shortlist. Since a database may contain qualitative information about offers (e.g. type of building, photos), this shortlist can be used as a first step in defining which offers should be physically viewed.
Fig. 1: Flow chart describing the purchase of a flat via the shortlist heuristic.
Section 1 describes the general form of the algorithm. Section 2 presents a simple example illustrating how the algorithm is applied. Section 3 gives results based on a real data set. Finally, some conclusions are made, together with directions for future research.
Description of the algorithm
This section describes an algorithm for constructing a shortlist of length n from N offers based on k numeric traits, denoted x1, x2, …, xk . A shortlist should contain offers that a) are potentially very attractive to the DM, and b) show diversity in their characteristics. The second criterion is particularly useful when a DM has limited knowledge about a particular market. For example, if somebody looking for a flat comes from a different city, the benefits gained from viewing flats with different characteristics/locations may well outweigh those from viewing offers that are all very close to the assumed ideal in terms of size and location, since the DM is likely to make a better informed final choice. We construct a list that maximizes a weighted sum of the average scores of the offers on the list and the average distance between them. To do this, we must define i) a measure of the attractiveness of an offer, ii) a measure of the distance between offers, iii) a measure of the attractiveness of a shortlist [based on i) and ii)]. Note that the raw data required to define the k traits might include more than k variables (to be discussed in Section 2). Let x = (x1, x2, … , xk) be the vector of the values of the traits describing an offer and y = (y1, y2, …,ym) denote the vector of variables in the raw data. By assumption, m ≥ k (note that the variables contained in y might precisely correspond to the variables in x).
The general form of the algorithm is as follows:
The DM states a) the length of the required shortlist, b) the weight of each trait, c) the minimum, maximum and ideal values of each trait, and d) the weight ascribed to the diversity of offers on the shortlist. Since defining the weight of diversity is not intuitive, this could be done by defining the level of knowledge a DM has regarding the market involved as low, medium or high. The possible range of the scores of offers is independent of the number of traits considered. However, suppose that the raw data are standardized to lie in the interval [0,1]. The maximum distance between offers is Hence, the weight ascribed to diversity should also take the dimension of the data into consideration (this will be investigated in future research). The minimum and maximum values of each trait are assumed to define hard constraints that an offer must satisfy.
The number of offers satisfying the hard constraints is outputted. Based on this, the DM can choose to relax the constraints. If the number of offers satisfying the constraints is sufficient, then any offer not satisfying the constraints is eliminated.
The overall score of each offer and the distance between each pair of offers is calculated (see below).
If the size of the shortlist is relatively small, an exhaustive search procedure may be used to find the shortlist maximizing the weighted sum of the mean score of the offers and the mean distance between them (this sum is defined below). The algorithm is designed to be used online and the shortlist produced will generally be of at least moderate size (e.g., tens of offers). Hence, the following greedy algorithm is used to find a near-optimal solution in a short time. Initially, the offer with the highest overall score is placed on the shortlist. The algorithm then successively adds offers to the shortlist until the required size has been attained. At each stage the weighted sum of the mean overall score and mean distance between offers is maximized. This is illustrated in Section 2.
Suppose ximin, ximaxand xiidealare the minimum, maximum and ideal values of trait i. The values ximin, ximaxare called the extreme values of a trait. Let fi (xi,) be the score of trait i when it takes the value xi. This score is defined to be one at the ideal value, zero at any extreme value not equal to the ideal value, and vary linearly between the ideal value and any extreme value differing from the ideal value. The function fi takes one of three forms depending on whether the ideal value is the minimum value, an intermediate value or the maximum. When ximin = xiideal, i.e., the minimum value is the ideal value,
In this case, the score according to trait i decreases linearly from 1 at ximinto 0 at ximax. When ximax= xiideal, i.e. the maximum value is the ideal value,
In this case, the score according to trait i increases linearly from 0 at ximinto 1 at ximax. Otherwise, i.e. when the ideal value of a trait is intermediate,
In this case, the score according to trait i is a triangular function taking the value of one at the ideal value and the value of zero at the extreme values. Let wi be the weight of the i-th trait. These weights are non-negative and sum to one. The overall score of an offer is f(x), where
Hence, the overall score of an offer is a weighted average of the scores according to the traits. Let f(xj) denote the overall score of the j-th offer.
Now we define the measure of distance between offers. Firstly, each variable in the data set is linearly scaled, so that the minimum value is zero and the maximum value observed is one. Hence, the scaled value of yi, denoted by yis, is given by
where yiminand yimax are the minimum and maximum, respectively, of the values of the i-th variable in the data matrix. Let D(yj , yl) denote the Euclidean distance between offers j and l according to these standardized values. This is illustrated in Section 2.
The score of the shortlist given by the set of offers S is a weighted sum of the scores of the offers and the mean distance between these offers. Let #(S) denote the number of offers in S and v denote the weight ascribed to the diversity within the shortlist. The number of pairs of offers in S is 0.5#(S)[#(S)-1].
We denote the score of the shortlist S by g(S), where
Note that this algorithm is flexible enough to be applied in conjunction with other approaches to multi-criteria decision problems, e.g. TOPSIS. Also, the algorithm can be used to form a shortlist of attractive offers that satisfy a budget constraint by using price as a variable, but giving it a weight of zero in defining the attractiveness score. The algorithm is designed to use data from continuous distributions. However, it is possible to use discrete variables (as illustrated in Section 3).
A Simple Example
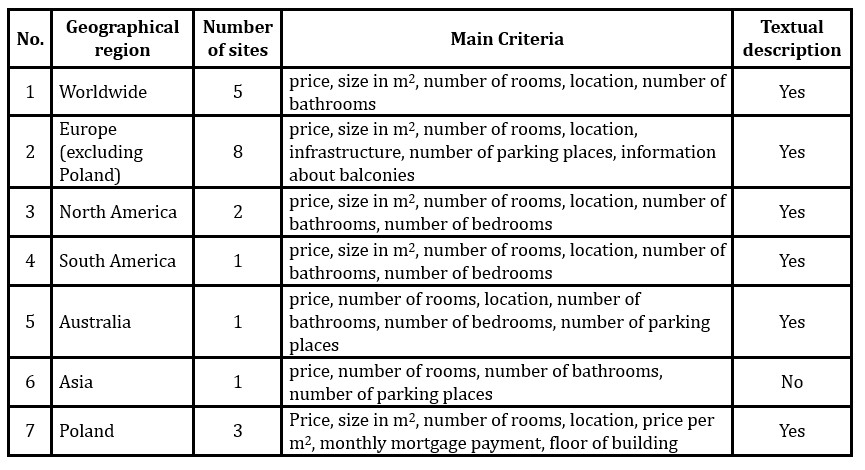
The algorithm uses easily accessible quantitative data. Although the seller decides which information is available, by not taking into account traits significant to clients, the seller would lose business. Dickinger and Mazanec (2008: 244-254) find that for any type of customer looking for a hotel room price, location and ratings from other customers are always important. Hence, Internet search engines for choosing accommodation highlight these criteria. The authors made an overview of real estate databases on the Internet to see how offers are presented (see Table 1). Kok et al (2017: 202-211) consider a similar problem from the point of view of an estate agent wishing to value properties in a large database.
Information is always given about price and the number of rooms. Also, nearly all sites give information on size in m2 and location. Furthermore, in 17 student projects on consumer decisions in the real estate market in Poland supervised by the authors, size and price were always found to be significant and the number of rooms was found to be significant in 16 of the analyses. Location was found to be significant by a large majority of studies. The following example illustrates the selection of a shortlist based on three traits: price, size in m2 and location. The first two traits are simply two variables from the data set.
Table 1: The main information given about new flats for sale according to geographic region (Based on a survey by the authors)
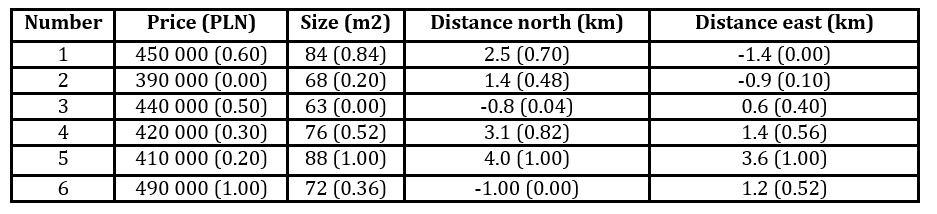
The definition of location is more problematic. In a number of projects, location was interpreted as the attractiveness of the district in which a flat is located, while in others it was measured as the distance from the city center. For the purposes of this study, distance from a reference point (to be chosen by the user) is a suitable variable to analyze. However, when considering the distance between two offers, this should depend on the physical distance between the flats and not on the differences between the distances to the reference point. Hence, the data required are the variables (y1, y2, y3, y4), where y1 is the price, y2 is the size in m2, y3 and y4 are the co-ordinates of the flat with respect to the reference point, e.g. distance north and distance east in kilometers.
Consider the following toy example. A client wishes to buy a new flat at a price between 300 000PLN and 500 000PLN (the ideal price is the minimum price), within 10km of his/her place of work (the ideal distance is 0). The size of the flat should be between 60m2 and 100m2 with an ideal of 80m2. The weights of price, location and size are 0.4, 0.3 and 0.3, respectively. There are six offers meeting the required criteria and we wish to form a shortlist of three offers when the weight ascribed to diversity is 0.3. Table 2 gives the raw data and their standardized values.
Table 2: Raw data and standardized data (in brackets) for the toy example
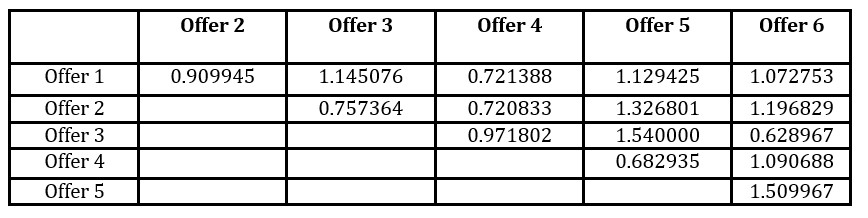
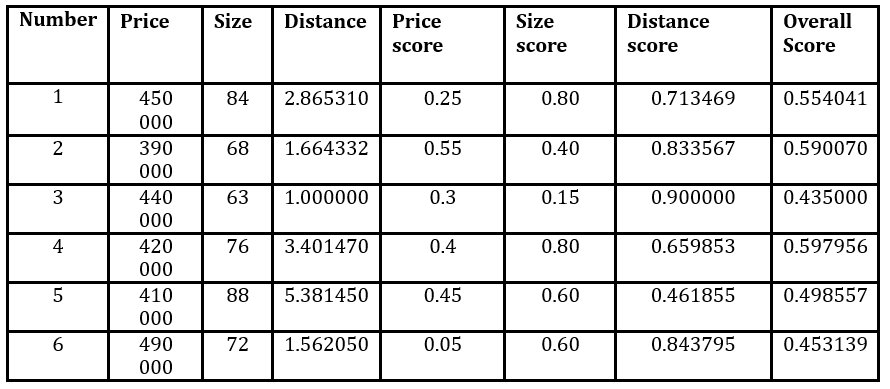
Table 3 gives the matrix of standardized distances between the offers. Table 4 gives the scores according to each trait and the overall score.
Table 3: Distances between the offers
When no weight is placed on the diversity of offers, then the optimal shortlist of length three simply contains the offers with the highest scores: offers 4, 2 and 1. Assume that the weight ascribed to diversity is 0.3. Applying the algorithm described above, the first offer placed in the shortlist is flat 4 (it has the highest overall score).
Table 4: Scores of the offers using Simple Additive Weighting with weights w1=0.4, w2=w3=0.3.
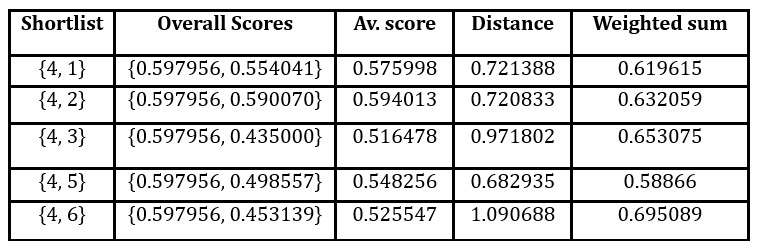
In the second stage, we select the shortlist of length two including flat 4 that maximizes the weighted average of the mean score and diversity. These calculations are illustrated in Table 5.
Table 5: Choice of the second offer to be placed on the shortlist
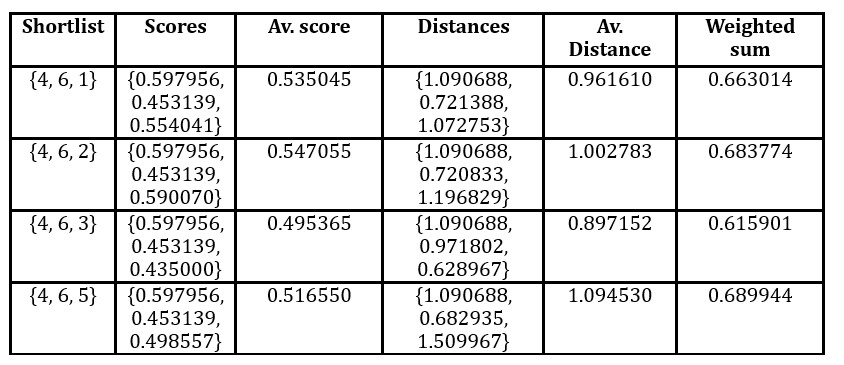
Adding offer 6 maximizes this weighted average over such shortlists. At the final stage of the algorithm, we consider shortlists of length 3 that include offers 4 and 6. These calculations are illustrated in Table 6. The shortlist generated consists of offers 4, 5 and 6.
Table 6: Choice of the third offer to be placed on the shortlist
Note that in the i-th step of n in the algorithm, the best of N-i+1 shortlists is chosen. Hence, the total number of shortlists considered is
Exhaustive search over all the possible shortlists must consider possible solutions. In this example, the greedy algorithm considers 15 shortlists, while exhaustive search compares 20 shortlists of length three. Hence, there is little to gain from using the greedy algorithm. However, when N is very large and n reasonably large, the reduction in run time can be significant. Exhaustive search indicates that the optimal shortlist consists of offers 2, 5 and 6.
Using a real data set: searching for a flat in Wrocław, Poland
This Internet site https://www.otodom.pl/ (accessed 14/4/2020) contains information on approximately 10 000 properties in Wrocław. Suppose that the length of the required shortlist is six. Three traits were considered: price, surface area and number of rooms. The associated criteria, together with their weights, are:
Price: minimum 200 000 PLN, maximum 500 000 PLN, ideal value 200 000, weight 0.6.
Area: minimum 50 m2, maximum 100 m2, ideal value 80 m2, weight 0.3.
Number of rooms: minimum 2, maximum 4, ideal value 3, weight 0.1.
Note that number of rooms is a discrete variable and the score ascribed to this trait is a 0-1 function. Flats with two or four rooms are acceptable, but obtain a score of zero according to this trait. Flats with three rooms obtain a score of one according to this trait.
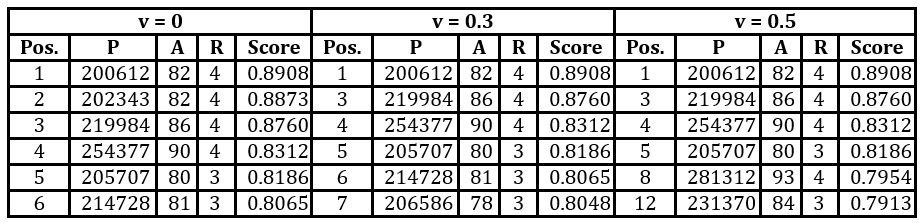
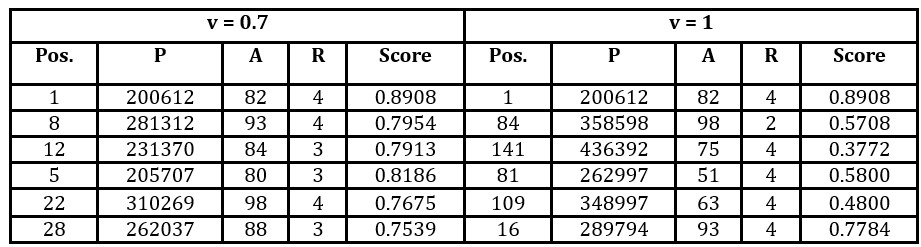
There were 195 properties satisfying the criteria. The algorithm was applied five times with differing values of the weight, v, ascribed to diversity: 0, 0.3, 0.5, 0.7 and 1. The weight 1-v is ascribed to the mean score of offers. When v=0, the algorithm returns the six most highly ranked offers based on the SAW method. When v=1, the algorithm returns the most diverse range of offers satisfying the criteria and including the one with the highest score. The results are illustrated in Tables 7 and 8.
Table 7: Shortlists constructed for different weights ascribed to diversity, v. The offers are placed in the order that they are added to the shortlist
Key: Pos. – ranking according to the SAW method, P – price, A – area in m2, R – no. of rooms.
Table 8: The shortlists constructed according to the weight ascribed to diversity, v. The offers are placed according to the order in which they are added to the shortlist
Key: Pos. – ranking according to the SAW method, P – price, A – area in m2, R – no. of rooms.
For this problem, when the weight ascribed to diversity does not exceed 0.5, then the algorithm returns a shortlist of offers that are all very highly ranked (in the top 12 of the 195 offers satisfying the criteria). Future research will investigate how to determine a suitable value for this weight according to the preferences and knowledge of the DM.
Results and Conclusions
This article has presented an algorithm for producing shortlists of offers from a large database, which may be used when DMs are looking for a unique and valuable resource (e.g. a flat or second-hand car). Such shortlists present a diverse set of potentially attractive offers by maximizing a weighted sum of the mean scores of the offers on the shortlist and the mean distance between them. The weights ascribed to each trait (at the level of determining the score of an offer) and the diversity of offers (at the level of determining the attractiveness of a shortlist) have a significant effect on the set of offers placed on the shortlist. Hence, future research will investigate the robustness of such approaches with respect to these parameters. In particular, the weight ascribed to the diversity of a shortlist should be adapted to a) the clarity of the preferences (or market knowledge) of the DM, and b) the number of variables in the data matrix.
Future research should also consider how robust the algorithm is to the distribution of the raw data. For example, the coefficient of variation of the variables observed may be very different. This can lead to problems in the standardization procedure, e.g. if a city lies in a long valley running from east to west, then a physical distance between two offers in the north-south direction will have a much larger standardized value than the same physical distance between two offers in the east-west direction.
The algorithm presented here is flexible enough to be implemented using any of the wide range of methods available for assessing offers based on multiple traits (e.g. TOPSIS, MARS). Hence, future research should also compare the effectiveness of such methods when adapted to the problem of choosing a shortlist of offers.
Although the algorithm is designed to be applied to continuous traits, discrete traits may also be considered. Future research will consider in more detail how discrete traits should be incorporated into the algorithm.
Another aspect that should be investigated lies in the fact that there may be a conflict of interest between the DM and an organization that gives access to such an algorithm. For example, an Internet site providing data about flats for sale might be more interested in selling flats from a particular developer or those that have been on the market for some time. Such problems are intrinsically game theoretic.
Acknowledgements
This work is supported by the Department of Operations Research and Business Intelligence, Wrocław University of Science and Technology from statutory research funds obtained from the Ministry of Science and Higher Education. David Ramsey and Aleksander Mariański are grateful to funds obtained from the Polish National Science Centre for project number 2018/29/B/HS4/02857, “Logistics, Trade and Consumer Decisions in the Age of the Internet”.
Armouti-Hansen, J. and Kops, C. (2018), This or that? Sequential rationalization of indecisive choice behavior. Theory and Decision, 84(4), 507–524.
Au, P. H. and Kawai, K. (2011), Sequentially rationalizable choice with transitive rationales. Games and Economic Behavior, 73(2), 608-614.
Belton, V. (1985), The use of a simple multiple-criteria model to assist in selection from a shortlist. Journal of the Operational Research Society 36(4), 265-274.
Borah, A. and Kops, C. (2019), Rational choices: an ecological approach. Theory and Decision, 86(3-4), 401-420.
Dickinger, A. and Mazanec, J. A. (2008), Consumers’ preferred criteria for hotel online booking. InENTER, January (pp. 244-254).
Durbach, I. and Davis, S. (2012), Decision support for selecting a shortlist of electricity-saving options: A modified SMAA approach. ORiON, 28(2), 99-116.
Dulleck, U., Hackl, F., Weiss, B. and Winter-Ebmer, R. (2011), Buying online: An analysis of shopbot visitors. German Economic Review, 12(4), 395-408.
Górecka, D., Roszkowska, E. and Wachowicz, T. (2016), The MARS approach in the verbal and holistic evaluation of the negotiation template. Group Decision and Negotiation, 25(6), 1097-1136.
Kaliszewski, I. and Podkopaev, D. (2016), Simple additive weighting—A metamodel for multiple criteria decision analysis methods. Expert Systems with Applications, 54, 155-161.
Kok, N., Koponen, E-L. and Martinez-Barbosa, C.A. (2017), Big Data in Real Estate? From Manual Appraisal to Automated Valuation, The Journal of Portfolio Management, 43(6), 202-211.
Lleras, J. S., Masatlioglu, Y., Nakajima, D. and Ozbay, E. Y. (2017), When more is less: Limited consideration. Journal of Economic Theory, 170, 70–85.
Manzini, P. and Mariotti, M. (2007), Sequentially rationalizable choice. American Economic Review, 97(5), 1824-1839.
Masatlioglu, Y., Nakajima, D. and Ozbay, E. Y. (2012), Revealed attention. American Economic Review, 102(5), 2183-2205.
Olkin, I. and Stephens, M. A. (1993), On making the shortlist for the selection of candidates. International Statistical Review/Revue Internationale de Statistique, 477-486.
Ramsey, D. M. (2019), Optimal Selection from a set of offers using a shortlist. Multiple Criteria Decision Making, 14, 75-92.
Schwartz, B. (2004), The paradox of choice: Why more is less. New York: Ecco.
Simon, H. A. (1956), Rational choice and the structure of the environment. Psychological Review, 63(2), 129.
Todd, P. M. and Gigerenzer, G. (2000), Précis of simple heuristics that make us smart. Behavioral and Brain Sciences, 23(5), 727-741.
Yoon, K. P. and Hwang, C. L. (1995), Multiple attribute decision making: an introduction (Vol. 104). Sage publications.