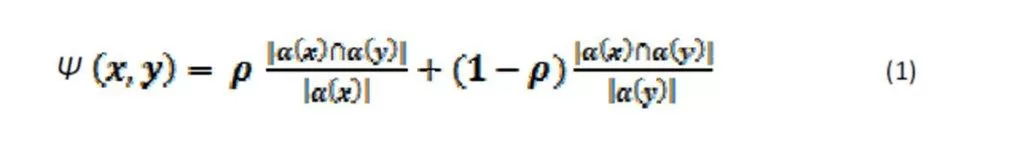Figure 5: Comparison of semantic similarity between proposed model and FCFS
Fig. 5 shows that most of the Gridlets are scheduled on high semantic relevant resources in the proposed model as compared to FCFS scheduling. In FCFS, users have a low chance to get a high degree of relevant resources as compared to the proposed model even when the best semantic similarity resources are available. However, in the proposed model, most of the time, users get high semantic relevant resources. Each Gridlet has its own requirement and we inject the same type of requirement of Gridlet in both models to fair comparison. It is noted that there is no proportion between semantic similarity and Gridlet value so the increase in number of Gridlets cannot affect semantic similarity values.
Conclusion and Future work
In this paper, a novel optimization model has been presented that selects optimal Grid resources for scheduling user jobs by considering proximity and semantic similarities values. The model is designed and implemented when a gap is identified in an existing FCFS allocation scheme for a semantic decentralized resource discovery. To overcome the gap, the proposed model utilizes the best combination of proximity and semantic values of available Grid resources and enhances the Grid performance. The experimental results verified that the proposed model provides benefits in the allocations of most suitable resources. The experimental results are compared with the existing FCFS scheduling that shows that the proposed model outperforms in terms of proximity and semantic similarity. In the future work, we would like to extend the ontology of Grid resources and implement and deploy the proposed model in real Grid system with real world applications.
References
1. Andreasen, T., Bulskov, H., & Knappe, R. (2003). From ontology over similarity to query evaluation. Paper presented at the 2nd CologNET-ElsNET Symposium-Questions and Answer: Theoretical and Applied Perspective, Amsterdam, Holland.
2. Buyya, R., & Murshed, M. (2002). GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for Grid computing. Concurrency and Computation: Practice and Experience, 14(13-15), 1175-1220.
3. Chen, L., & Tao, F. (2008). An Intelligent Recommender System for Web Resource Discovery and Selection Intelligent Decision and Policy Making Support Systems (pp. 113-140).
4. Druschel, P., Haeberlen, A., Hoye, J., Iyer, S., Mislove, A., Nandi, A., . . . Singh, A. (2012). Free Pastry Software Retrieved Jan 20, 2012, from http://www.freepastry.org/FreePastry/
5. Iamnitchi, A., Foster, I., & Nurmi, D. C. (2003). A peer-to-peer approach to resource location in grid environments INTERNATIONAL SERIES IN OPERATIONS RESEARCH AND MANAGEMENT SCIENCE (pp. 413-430): Springer.
6. Karaoglanoglou, K. I., & Karatza, H. D. (2009). Performance evaluation of a resource discovery scheme in a Grid environment prone to resource failures. Paper presented at the Parallel & Distributed Processing, 2009. IPDPS 2009. IEEE International Symposium on.
7. Li., J. (2010). Grid resource discovery based on semantically linked virtual organizations. Future Generation Computer Systems, 26(3), 361-373.
8. Liangxiu, H., & Berry, D. (2008). Semantic-Supported and Agent-Based Decentralized Grid Resource Discovery. Future Generation Computer Systems, 24(8), 806-812.
9. Lua, E. K., Crowcroft, J., Pias, M., Sharma, R., & Lim, S. (2005). A survey and comparison of peer-to-peer overlay network schemes. IEEE Communications Surveys and Tutorials, 7(2), 72-93.
10. Pirrò, G., Talia, D., & Trunfio, P. (2012). A DHT-based semantic overlay network for service discovery. Future Generation Computer Systems, 28(4), 689-707.
11. Qureshi, M. B., Dehnavi, M. M., Min-Allah, N., Qureshi, M. S., Hussain, H., Rentifis, I., . . . Xu, C.-Z. (2014). Survey on Grid Resource Allocation Mechanisms. Journal of Grid Computing, 1-43.
12. Ranjan, R., & Buyya, R. (2009). Decentralized overlay for federation of Enterprise Clouds. Handbook of Research on Scalable Computing Technologies, 191.
13. Ranjan, R., & Buyya, R. (2009). Decentralized Overlay for Federation of Enterprise Clouds, Handbook of Research on Scalable Computing Technologies. USA IGI Global.
14. Rowstron, A., & Druschel, P. (2001). Pastry: Scalable, decentralized object location, and routing for large-scale peer-to-peer systems.
15. Schwering, A. (2008). Approaches to Semantic Similarity Measurement for Geo-Spatial Data: A Survey. Transactions in GIS, 12(1), 5-29.
16. Shaikh, A., Alhashmi, S., & Parthiban, R. (2012). A Semantic Impact in Decentralized Resource Discovery Mechanism for Grid Computing Environments. In Y. Xiang, I. Stojmenovic, B. O. Apduhan, G. Wang, K. Nakano & A. Zomaya (Eds.), Algorithms and Architectures for Parallel Processing (Vol. 7440, pp. 206-216): Springer Berlin Heidelberg.
17. Shaikh, A., Alhashmi, S., & Parthiban, R. (2013). Ontology-based Decentralized Resource Provisioning in Economic Grids. Paper presented at the Proc. 20th International Conference on Business Information Management Association Kuala Lumpur, Malaysia.
18. Somasundaram, T., Govindarajan, K., Kiruthika, U., & Buyya, R. (2014). Semantic-enabled CARE Resource Broker (SeCRB) for managing grid and cloud environment. The Journal of Supercomputing, 68(2), 509-556. doi: 10.1007/s11227-013-1047-z.
19. Standford. (2011). Ontology Editor & Knowledge base Framework. Retrieved 12 Dec 2011, from http://protege.stanford.edu/.
20. Stoica, I., Morris, R., Liben-Nowell, D., Karger, D. R., Kaashoek, M. F., Dabek, F., & Balakrishnan, H. (2003). Chord: a scalable peer-to-peer lookup protocol for internet applications. Networking, IEEE/ACM Transactions on, 11(1), 17-32.
21. Tam, D., Azimi, R., & Jacobsen, H. A. (2004). Building content-based publish/subscribe systems with distributed hash tables. Databases, Information Systems, and Peer-to-Peer Computing, 138-152.
22. Tao, Y., Jin, H., Wu, S., & Shi, X. (2009). Scalable DHT- and ontology-based information service for large-scale grids. Future Generation Computer Systems, 26(5), 729-739.
23. Vidal, A. C. T., Jos, F., Silva, d. S. e., Kofuji, S. T., & Kon, F. (2007). Semantics-based grid resource management. Paper presented at the 5th international workshop on Middleware for grid computing, Newport Beach, California.
Experiment
Two discrete event based simulators i.e. GridSim and FreePastry are integrated to measure the efficiency of both Grid entities and network related performance metrics. The proposed model deployed the algorithm in the sub-domain ontology structure to improve the recall values. The proposed model uses the unification of proximity and semantic similarities values in the selection process of resources for user jobs. The performance of the model is highly dependent on the number of ontology concepts and the semantic threshold values set by users. We have run the simulations with the following set of parameters. The experiment configuration is shown in the following table:
Table 3: Experiment Configurations