Introduction
The world computing infrastructure is developing from large scale distributed systems and peer-to-peer systems to the recently deployed grid and cloud computing. There is an acceptable notion stated that there is a trend towards distribution and decentralization of information technology resources, which is at the same time confronted with the need for consolidated and efficient use of these resources. Hence, “This results in several problems such as ever increasing demand for storage and computing power at each data centre, many and scattered data centers with underutilization of their resources, and increasing maintenance costs of data centers” (Stanoevska-Slabeva, Wozniak and Ristol, 2010, p.18).
Trough the history of information processing, the computer technology and the application design consisted constant development and improvement in order to make business more efficient, more manageable and more concurrent that is especially of importance in the globalized economy. In the time of centralized systems, the computer systems were not interconnected and information was on media storage that was the tool for moving computerized data from one to another place of entire business organization. This scenario has been changing by distributed systems that started as the management model in the stage of minicomputers implementation, and it has been raised by personal computers dissemination through the organization sites. The computers and their data were often isolated from the main processing and business network. Thus, there was the need for connectivity and data integration. Once personal computers became part of the overall computing strategy, the problem of successful managing of these distributed systems begins to affect every serious business strategy. Because the enterprise computing environment became increasingly difficult to manage, distributed information processing took a place as the central solution for system management success. This trend continued with the Web platforms that created new possibilities for integration and platform independence. This also created the ability to provide centralized management of Web servers. New Web-based systems are complex combinations of networking and computing technology. Thus, a new distributed services model for management was created. Internal and external users of the systems were connected to many different applications, hosted on many different servers. The fundamental information models built for office and enterprise networks are useful for sharing files and executing transactions, but they simply do not fill the needs of embedded systems. In real-time networks, the main problem still exists and it is consider finding and disseminating information quickly to many nodes. These problems are the object of grid and cloud computing scenarios introduced primarily to fully capture current information technology capabilities for producing the most efficient information processing system that modern business need.
Through the process of distributed systems development, the distributed computing area has been characterized by the deployment of large-scale grids that have provided the research and business community with an unprecedented number of resources. Despite current efforts to make the grids unified, the heterogeneity of hardware and software has contributed to increasing complexity of deploying applications on these infrastructures. Moreover, recent advances in virtualization technologies have led to the emergence of commercial infrastructures deployed as cloud computing services. At the same time, the increasing ubiquity of virtual machine technologies has enabled the creation of customized environments atop physical infrastructure with new business models. Existing virtual-machine based resource management systems can manage a cluster of computers within a site allowing the creation of virtual workspaces or virtual clusters. These issues are correlating to the term of delegation by which the system management, data processing functions, and information are delegated through the federation of systems and services.
Thus, new forms of management and services are needed in the context of distributed system maturation through the cloud computing deployment. The process of upgrading grid computing concepts resulted with the cloud computing portfolio that is still in developing phase. Hence, the cloud computing is conceived today as a large pool of easily usable and accessible virtualized resources (such as hardware, development platforms and/or services). These resources can be dynamically reconfigured to adjust to a variable load (scale), providing also an optimum resource utilization. This pool of resources is typically exploited by a pay per-use model in which the Infrastructure Provider offers guarantees by means of customized service level agreements (Vaquero et al., 2009).
The business goals are always about costs of production and good return on investment (ROI) that makes pressure to the information professionals finding proper solutions for today’s dynamic, mobile and globalized business. Thus, the cloud computing associated with a new paradigm for the provision of computing infrastructure shifts the location of information-communication system operations to the open network in order to reduce the costs associated with the management of hardware and software resources. The concept of cloud computing is drawing the attention from the information and communication technology community, thanks to the appearance of a set of services with common characteristics. However, some of the existing technologies the cloud computing concept draws on (such as virtualization, utility computing or distributed computing) are not new. Hence, the idea is to develop cloud computing portfolio toward delegated information processing system that would fully comply with new business demand for technology and information resources.
Information-Communications System Convergence
Information-communications systems are the core element of the new forms of social life, culture, and business transforming them into digital environment of the new media society. New media society needs new forms of information processing agreements and regulation with intersectoral structure comprising frameworks in three basic sectors that are creating information-communications systems paradigm:
- network (all forms of fixed, mobile, intelligent and integrated telecommunications on local regional and global basis)
- digital data/information transportation
- receiver (user/customer, audience)
- digital information/content (personal, public, broadcasted)
Each of the sectors is faced with new media opportunities and drawbacks that are reshaping the current working and life environment. Furthermore, there are new forms of relationships, roles, rights and duties for each business firm acting in new digital economy. All of these facets ask for new forms of managed activities making the base on which new forms of information processing will work in the best way for all participants.
Although personal computers and Internet will come invisible or disappear from the information technology scene, these technologies tend to stipulate new technologies and services. The trend is also visible with the miniaturization of applications systems existing on today’s Internet based global services — it is resulted in open business and home systems that must be tailored for the individual use, and suited to personal interest and demand. That is the point where today’s Web solutions are not yet prepared to work out this task.
The impact of new information-communications systems technology on electronic business (e-business) is enormous. Although teleworking has failed to take off anywhere near as fast as many e-business expected, technologies such as shared virtual environment, broadband network access, multimedia and mobile communications are changing this situations promising new wave in e-business applications. Besides that, the new information-communications system concept impacts on e-business practices. It offers the potential for major new business and industrial opportunities, but e-business companies will only benefit for this if they are prepared to be creative, innovative and intelligent. Many modern applications require considerable cross-sector capabilities and cooperation. Currently and in nearly future, the critical technologies for e-business environment are:
- Open and transparent communications infrastructure
- Simulation and data visualization
These critical technologies form the basis for new services deployed through the advanced distributed systems concept deployed by grid and cloud computing. The result of information-communications systems development is information content space where information users and intelligent agents can directly tap the latest relevant information in linked and related information resources. This help free information users from having its own dedicated information processing system. At the same time, it resulted in the techniques that outfit information users with personal information portals and search/intelligent agents tailored to their particular information needs. The process includes information appliances that could be configured to learn and respond to personal details with the help of artificial intelligence techniques. Hence, information, as well as the infrastructure, is becoming a service. In the context of paradigm ‘information as a service’, information in any form like images, documents, real time data etc. is brought together into a single location. It is obvious that the unified provisioning and management of services framework becomes very important characteristic of information market place on which modern business relies.
Distributed Information Processing
It is often argued that the labor productivity increase is due to the widespread introduction of new information and communication technologies. The introduction of new information and communication technologies allows organizations to process any given amount of information with a shorter delay, enabling them to restructure and solve incentive problems without risking to produce with excessive delay. Even a marginal improvement in the information technology can yield significant increases in labor productivity if the organization is drastically restructured (Grüner, 2009). These notions are close to the thoughts on restructuring data processing management, too. Further, these issues are correlating with the distributed data processing scenarios developed in order to improve overall business productivity.
The problems of distributed systems management did not exist in the early stage of mainframe computing scenarios. Systems were centralized and typically housed in one facility. Over time, however, the power, complexity and connectivity of the computer systems and networks evolved. Westerinen and Bumpus (2003) argue that businesses today are dependent on their compute and networking infrastructures to operate and survive. These infrastructures are geographically and functionally distributed, and their management is critical. Once personal computers became part of the overall computing strategy in many businesses, systems management was changed dramatically. Data centers were not only concerned with management of the central or mainframe computers that they owned, but were also faced with the management of hundreds or thousands of mini data centers and personal computers spread over large geographic areas. Most of the early focus on distributed systems management was on software upgrades, system configuration management, and software and hardware inventory.
Besides, the development of the local area network technologies provided new possibilities for sharing information resources. Shared resources required new forms of activities for managing applications and databases. Also new applications were being developed as client-server applications, and they were distributing information processing over the network. This new paradigm shaped the new kind of data processing, since the enterprise computing environment became increasingly difficult to manage. In order to achieve the integration of management information, it was necessary to define and standardize procedures as well as common concepts and semantics of the managed components. Hence, the various models for information management, including the well-known Common Information Model, were developed. This model provided a way to represent not only the managed components, but also the interfaces (operations) and relationships between these components. It puts in place the basic semantics for systems, software and network management, and as object-oriented information model, allows subclassing, abstraction and encapsulation.
The major distributed computing platforms generally have two methods of porting applications. One kind of solutions relates to the software development kits that can be used to wrap existing applications with their platform. Other solutions offer application programming interface of varying complexity that require access to the source code, but provide tight integration, and access to the security, management, and other features of the platforms. Obviously, not all applications are suitable for distributed computing. The closer an application gets to running in real time, the less appropriate it is. Even processing tasks that normally take a short time may not derive much benefit if the communications among distributed systems and the constantly changing availability of processing clients becomes a bottleneck. Generally, the most appropriate applications consist of loosely coupled, non-sequential tasks in batch processes with a high compute-to-data ratio. In this sense, programs with large databases that can be easily parsed for distribution are very appropriate. Clearly, any application with individual tasks that need access to huge data sets will be more appropriate for larger systems than individual desktop computers. If huge data sets are involved, server and other dedicated system clusters will be more appropriate for other slightly less data intensive applications. For a distributed application using numerous desktop computers, the required data should fit very comfortably in the desktop computer memory, with lots of room to spare. According to Yabandeh et al. (2010), the implementation of a distributed system often contains the basic algorithm coupled with a strategy for making choices. Examples of choice include choosing a node to join the system, choosing the node to forward a message to, or choosing how to adapt to a change in the underlying network.
The information is for a long time out there, and the network infrastructure is reliable. The whole classes of new distributed applications are available, if the data were on disposal in adequate manner. However, the modern business rich of information assets is confronted with the complex and allocated information that are needed for doing business better and more cost effective. Distributed computing provides efficient usage of existing system resources. Estimates by various analysts have indicated that up to 90 percent of the computing power on a company’s client systems are not used. Even servers and other systems spread across multiple departments are typically used inefficiently, with some applications starved for server power while elsewhere in the organization server power is underutilized. Moreover, server and workstation obsolescence can be staved off considerably longer by allocating certain applications to a grid of client machines or servers. Thus, instead of throwing away obsolete desktop computers and servers, an organization can dedicate them to distributed computing tasks.
For today, however, the specific promise of distributed computing lies mostly in harnessing the system resources which lie within the firewall. It will take years before the systems globally networked will be sharing compute resources as effortlessly as they can share information. The fundamental information models built in past for office and enterprise networks were appropriate for sharing files and executing transactions, but they simply did not fill the needs of currently widespread embedded systems. In real-time networks, the main problem is to find and disseminate information functionally and quickly to many nodes distributed across the business domain. This problem is not yet completely solved, although the middleware, a class of software serving distributed applications by delivering data, is a promise to connect the ubiquitous network stack and the user applications.
Recently, general embedded middleware technologies have begun emerging; it shows promise for standardized, easy distributed data access. If middleware can deliver on that promise, it has the potential to fuel an explosion in embedded applications that parallels the enterprise growth of information technology deployment. In the recent time, it is obvious that the fastest-growing embedded middleware technologies are publish-subscribe architectures. In contrast to the central server with many clients model of enterprise middleware, publish-subscribe nodes simply subscribe to data they need and publish information they produce. This design mirrors time-critical information delivery systems in everyday business tasks. Thus, embedded middleware is crossing the threshold from specialized point solution to widely adopted infrastructure delivering solutions for new distributed systems with much greater capabilities than are practical today.
The next evolving technology that allows the development of distributed information processing components is about Web Services. These components can be integrated into a generic component based framework on the Web for large and complex distributed application development (Kumar, 2005). Hence, in most cases today, a distributed computing architecture consists of very lightweight software agents installed on a number of client systems, and one or more dedicated distributed computing management servers. Hence, an agent running on a processing client detects when the system is idle, notifies the management server that the system is available for processing, and usually requests an application package. The client then receives an application package from the server and runs the software when it has spare resources work, and sends the results back to the server. If the user of the client system needs to run his own applications at any time, control is immediately returned, and processing of the distributed application package ends. Obviously, the complexity of a distributed computing architecture increases with the size and type of environment. A larger environment that includes multiple departments, partners, or participants across the Web requires complex resource identification, policy management, authentication, encryption, and secure sandboxing functionality. Resource identification is necessary to define the level of processing power, memory, and storage each system can contribute. That is why a policy management should be used to varying degrees in different types of distributed computing environments. According to the stated policy, security and workflow measures define which jobs and users get access to which systems, and who gets priority in various situations based on rank, deadlines, and the perceived importance of each business project. Thus, complex and also distributed, measures are necessary to prevent unauthorized access to systems and data within distributed systems that are meant to be inaccessible.
Distributed processing systems are evolutioning to the grid computing, as the way to provide users the ability to harness the power of large numbers of heterogeneous, distributed resources, enable users and applications to seamlessly access these resources to solve complex business. Business, data intensive, applications are no longer being developed as monolithic codes. Instead, standalone application components are combined to process the data in various ways. The applications can now be viewed as complex workflows, which consist of various transformations performed on the data (Blythe et al., 2003).
In an age of ever increasing information collection and the need to evaluate it, building information processing systems that utilize the all available compute resources, should stipulate the development of more sophisticated, distributed computing systems. Today, large data processing facilities provide significant compute capabilities, and utilizing distributed resources in a coherent way is much more powerful. Hence, distributed processing tools and techniques were currently during last decades, and they are still under evolution process. This evolution is continuing by storage and network performances growth, and by the ever-growing mobility and distribution of business resources. Distribution of affordable devices makes them often idle much of the time. Besides that, the ability to capture and share data is becoming increasingly easy and fast in real time. Much of the data is and will be captured and stored in perpetuity at corporate Web sites and in data centers. Some of what should be available may be accessible through the gates of these data centers. Contrary, distribution of affordable, cheap and free compute devices to the business firms and individual workers continues to grow. Although most of the resources such as cell phones, laptops, desktops, etc. sit idle much of the time, they can now all participate in the storage and processing of data. This notion is considering grid and cloud computing portfolios as the ways of distributed systems development process. This issue opens the way of the efforts in development and deployment of delegation in information system design. The next logical step was done with the interrogation of the cloud computing as the tool for problem solving in distributed business system organization, workflow planning, and the management of the whole set of distributed resources.
Distribution by Grid Computing
At its core, grid computing enables devices, regardless of their operating characteristics, to be virtually shared, managed and accessed across an enterprise, industry or workgroup. This virtualization of resources places all of the necessary access, data and processing power to those who need to rapidly solve complex business problems, conduct compute-intensive research and data analysis, and operate in real-time. The Internet or dedicated unified networks can be used to interconnect a wide variety of distributed computational resources (such as supercomputers, computer clusters, storage systems, data sources) and present them as a single, unified resource. The traditional client-server Internet model is beginning to give some ground to peer-to-peer networking, where all network participants are approximately equal. The enormous power of these networks is increasingly being blended with more complex grid computing. In this context, grid computing is often defined as applying resources from many computers in a network to a single problem, usually one that requires a large number of processing cycles or access to large amounts of data.
Taking various definitions into account, a grid computing presents a form of distributed computing, which provides a unified model of networked resources (processing, application, data, and storage) within and across organizations. The unified model presents a homogeneous view of collections of heterogeneous resources, and supports the dynamic coordination, sharing, selection and aggregation of these resources in order to meet users’ availability, capability, performance, and cost requirements. It is obviously that a grid computing matured from the distributed data processing system architecture and management developed in the early days after mainframe computers domination.
Foster and Kesselman (1998) brought the ideas of the grid computing (including those from distributed computing, object-oriented programming, and Web services). They stated that a computational grid is a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to high-end computational capabilities. In other words, it is a means of simultaneously applying the resources of many networked computers to a single problem. From the user perspective, grid computing means that computing power and resources can be obtained as utility. It means that the user can simply request information and computations and have them delivered to her or him without knowing where the data she or he requires resides, or which information appliance is processing her or his request (Goyal and Lawande, 2005). Grid computing has several similarities with the distributed processing conceptual model acting around the common objective: organizing the use of large sets of distributed resources. Hence, many important issues are common: scalability, communication performance, fault tolerance, and security.
At the same time, grid computing means the virtualization and sharing of available computing and data resources among different organizational and physical domains. The increasing ubiquity of virtual machine technologies has enabled the creation of customized environments over physical infrastructure and the emergence of business models including grid and cloud computing. The use of virtual machine technologies brings several benefits to business information processing management. Existing virtual-machine based resource management systems can manage a cluster of computers within a site allowing the creation of virtual workspaces or virtual clusters. These systems commonly provide an interface through which one can allocate and configure virtual machines with the operating system and software of choice. These resource managers allow the user to create customized virtual clusters using shares of the physical machines available at the site (Keahey et al., 2006).
Today’s business is confronted with the strong demand for agility in order to survive on globalized and turbulent markets. Business agility as the ability to easily change businesses and business processes beyond the normal level of flexibility to effectively manage unpredictable external and internal changes, asks for the prevailing information technology infrastructure of enterprises. An agile company is active only with an agile information technology infrastructure, which can be quickly and efficiently adjusted to new business needs and ideas. Besides the agility issues, there is globalization as well as mobility as the current portfolio under which companies are doing business. However, business traditionally performed computing tasks in highly integrated enterprise computing centers. Although sophisticated distributed systems existed, these were specialized, niche entities. The Internet’s rise and the emergence of e-business have led to a growing awareness that an enterprise’s internal information technology infrastructure also encompasses external networks, resources, and services. According to Foster et al. (2002), system developers treated this new source of complexity as a network-centric phenomenon and attempted to construct intelligent networks that intersected with traditional enterprise data centers only at edge servers that connect an enterprise network to service provider resources. These developers worked from the assumption that these servers could, thus, manage and circumscribe the impact of e-business and the Internet on an enterprise’s core information technology infrastructure.
Grid computing also relied on meta systems as collections of interconnected resources harnessed together in order to satisfy various needs of users (Smarr and Catlett, 1992). The resources may be administered by different organizations and may be distributed, heterogeneous, and fault-prone, and usage policies for the resources may vary widely. A grid infrastructure must manage this complexity so that users can interact with resources as easily and smoothly as possible. According to the distribution of resources and applications, Grimshaw and Natrajan (2005) defined a grid system as system that gathers resources and devices with embedded processing resources making them accessible to users and applications in order to reduce overhead and accelerate projects. They also defined a grid application as an application that operates in a grid environment. It is obvious that a grid enables users to collaborate securely by sharing processing, applications, and data across systems in order to facilitate collaboration, faster application execution, and easier access to data. The most used types of application in a grid environment are finding and sharing data, finding and sharing applications, and finding and sharing computing resources. Hence, the grid system software makes the middleware that facilitates writing grid applications and manages the underlying grid infrastructure.
Hence, grid computing has evolved into an important architecture differentiating itself from distributed computing through an increased focus on the grid structure that includes resource sharing, coordination, manageability, and high performance (Foster, Kesselman and Tuecke, 2001). Thus, these resources cannot be considered as grids, unless they are based on sharing: clusters, network-attached storage devices, scientific instruments, networks. In order to stipulate grid architecture development, the three-layer architecture has been proposed compounding the computation/data layer, information layer, and knowledge layer. Looking at basic model of grid architecture that Foster and Kesselman (1998) proposed, the three-layer grids architecture was the base for an Open Grid Services Architecture, based on W3C Web Services (Jeffery, 2002). Open Grid Services Architecture as a set of standards defines the way in which information is shared among diverse components of large, heterogeneous grid systems. In this context, a grid system is a scalable wide area network that supports resource sharing and distribution optimizing communication and interoperability among resources of all types.
Next generation grid systems are heading for globally collaborative, service-oriented and live information systems that exhibit a strong sense of automation. A collection of autonomous agents is searched, assembled, and coordinated in a grid middleware system to produce desirable grid services. An effective communication mechanism is vital to the effectiveness of the step to build a novel grid middleware system. Computing grids offer computing as a service through a collection of inexpensive managed nodes with some billing and job management software. As computer grids are commercially available, two fundamental challenges exist: trust asymmetry, and movement of data to and from the grid. Current grid solutions have many fundamental security problems, such as requiring sharing of keys and, trusting of the infrastructure deployed by the grid service provider. Traditional approaches attempt to secure an operating system so that operations on plain text can be carried out without concern. Many users will never trust a service provider enough and so they are orienting to the use of managed delegation of computing services.
Cloud Computing Environment
With the significant advances in information and communications technology over the last half century, there is an increasingly perceived vision that computing will one day be the utility, i.e. computing utility. This computing utility will provide the basic level of computing service that is considered essential to meet the everyday needs of the general business community. Thus, delivering this utility asks for new computing paradigms, of which the one is cloud computing (Buyya et al., 2009). Cloud computing aims to enable the dynamic creation of next-generation data centers by assembling services of networked virtual machines so that users are able to access applications from anywhere in the world on demand. Regarding the cloud computing definition and understanding its deployment environment, there is a need for standardized approach to the definition. This goal is temporary achieved by the National Institute of Standards and Technology that has provided a definition of cloud computing. The version 15 of October 7, 2009 defines cloud computing as a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
The current cloud computing scenarios shows the paradigm that cloud computing is presented as the combination of many preexisting technologies. These technologies have matured at different rates and in different contexts, and were not designed as a coherent whole. However, they have come together to create a technical ecosystem for cloud computing. New advances in processors, virtualization technology, disk storage, broadband Internet connection, and fast, inexpensive servers have combined to make the cloud a more compelling solution (Mather, Kumaraswamy and Latif, 2009, p.11).
The cloud computing is also seen as an incremental evolution from grid computing where cloud platforms are using traditional distributed systems mechanisms. This means that cloud computing brings new distributed computing models with high performance data storage systems. Further, the real decision on the type of the cloud computing scenarios depends on business goals and the type of organization of the entire business firm. Organizations with portfolios comprised of large scale, monolithic, tightly coupled applications needs complete information processing solution through the cloud computing portfolio. If such solution is impossible, they decide to leave cloud computing candidates. Organizations with portfolios based on well-defined services, with solutions assembled using service oriented constructs, are better positioned to take advantage of cloud computing financial benefits.
It is obvious that virtualization technologies have also facilitated the realization of cloud computing services. Cloud computing includes three kinds of services accessible by the Internet: software as a service, platform as a service, and infrastructure as a service (di Costanzo, Assuncao and Buyya, 2009). Today, the latest paradigm to emerge is that of cloud computing, which promises reliable services delivered through next-generation data centers that are built on compute and storage virtualization technologies. Consumers will be able to access applications and data from an information processing cloud anywhere in the world on demand. In other words, the cloud computing appears to be a single point of access for all the computing needs of business (Weiss, 2007).
One of the interesting attributes of cloud computing is elasticity of resources. This capability allows business users to increase and decrease their computing resources as needed. There is always an awareness of the baseline of computing resources, but predicting future needs is difficult, especially when demands are constantly changing. Cloud computing can deliver ubiquitous information services across the globe across any platform. It can be elastic in its demands on the infrastructure while the infrastructure and maintenance of it can be invisible to the individual users and the organization. It is supplied like a low-cost utility to the payers for a ‘pay for what you use’ model. Lastly, this allows organizations to focus on their business not on the information technology business (Velte, A., Velte, T. and Elsenpeter, 2009).
Thus, cloud computing can offer a means to provide information processing resources on demand and address spikes in usage. Cloud computing is elastic also in a term of deployment. That implies several drivers for moving applications into the cloud computing environment. Economics is the greatest force. Under traditional information processing system design, the corporate data center must be built to handle business information processing peak. The infrastructure should have been on disposal at all times, even at the minimum load for small application. For applications with seasonal implications, cloud computing brings a huge savings. Cloud computing lays on information technology infrastructure, where core infrastructure is presented as a service, and where accompanied computing utility appliances (hardware) are also presented as a service. Infrastructure is based on virtual or physical resources as a commodity to business users. Hence, the physical infrastructure is managed by the core middleware whose objectives are to provide an appropriate runtime environment for applications and to utilize the physical resources at best. Virtualization technologies provide features such as application isolation, quality of service, and sandboxing. Furthermore, the physical infrastructure and core middleware represent the platform where applications are deployed.
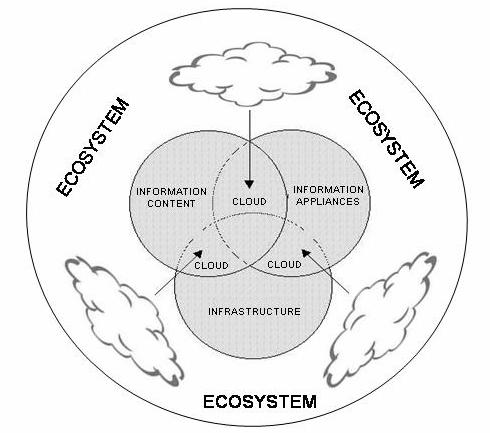
Hence, new ways of digital business models could be implemented through the entire business ecosystem. By its nature, business ecosystem is aiming to commercialize emerging ideas inside business dynamic environment and it fosters the information-communications ecosystem when information technology is in use. Information-communications ecosystem crosses business domains and different computer systems. Thus, it has no single functional reference model. Since it is not feasible to define all the required functional models, the ecosystem model is presented as schematic diagram of interconnectivity and interfunctionality of the functional categories. The main goal of distributed networks is to use a large number of nodes with variable connectivity in unified form in order to minimize central organization. This notion denotes the information-communications system development paradigm postulated by delegated information processing. In such environment, digital documents, business data, information content, and services move, by the cloud computing infrastructure and services, within the ecosystem (network), allowing delegated person, machine, service or application to interact with or share the data.
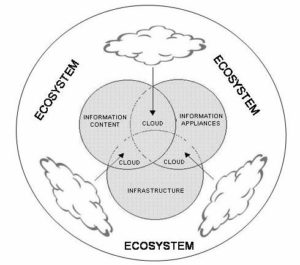
Fig 1. Schematic of the Information-Communications Ecosystem Model
In Figure 1, we could see the relations that users have with the cloud computing environment in which information processing tools (ubiquitous information appliances) and information/data bases placed within the entire environment. The user has the possibility to pick up any of the utility items in any time from any place within cloud environment. This platform is made available through a user level middleware, which provides environments and tools simplifying the development and the deployment of applications in the cloud computing environment. Hence, cloud computing is no longer a trend but an emerging deployment model that is reshaping the landscape of what and how the information managers manage information processing.
The term cloud is a metaphor for the Internet, and it is a simplified representation of the complex, inter-networked devices and connections that form the Internet. According to Mather (2009), there are two basic deployment models: private and public clouds as subsets of the Internet. These models are defined by their relationship to the enterprise. Private and public clouds may also be referred to as internal or external clouds; the differentiation is based on the relationship of the cloud to the enterprise. The public and private cloud concepts are important because they support cloud computing, which enables the provisioning of dynamic, scalable, virtualized resources over Internet connections by a vendor or an enterprise information processing department to customers (Mather, Kumaraswamy and Latif, 2009). At the same time, cloud computing is a new and promising paradigm delivering information and computing services as computing utilities. As cloud computing units are designed to provide services to external users, providers need to be compensated for sharing their resources and capabilities that open new computing utility market in some way. Further, as cloud computing platforms become ubiquitous, the need for internetworking them to create a market-oriented global cloud exchange for trading services becomes dominant (Buyya, Yeo and Venugopal, 2008).
To sum up, the evolution to cloud computing has advanced through such technological developments as service oriented architectures, collaboration software, and virtualization. Businesses are no longer operating within the confines of a traditional corporate boundary, but rather as part of a global ecosystem of supply chains, strategic alliances, and partnerships. Increasingly ubiquitous connectivity, coupled with advances in mobile device capabilities and strategies, as well as new and exciting collaboration and remote service delivery paradigms, have all begun to erode traditional corporate culture. Hence, the demand for interoperability and integration will likely drive a widely supported fabric of intracloud application programming interfaces that will be developed to link cloud-based systems across vendor platforms. This consolidation and integration, along with improved security, privacy, and governance enhancements, will broaden the appeal of cloud computing while building the trust of users, who will increasingly offload large portions of their information technology infrastructure to third parties. However, many consumers and companies are missing out on the entitlement, and policy enforcement. Businesses must think about tiered perimeters without abandoning core infrastructure. This has also resulted in new security challenges that organizations did not have to face when critical resources and transactions were behind their firewalls or controlled partner networks (Rittinghouse and Ransome, 2010).
The benefits of cloud computing are dealing strongly with the delegation of business information processing. Delegating workloads to a cloud computing environment provides information management to confront with the overwhelming information processing requirements from all of the staff members around the spread work locations.
Delegated Information Processing Development
Cloud computing provides a way to develop applications in a virtual environment, where computing capacity, bandwidth, storage, security and reliability are not issues. In a virtual computing environment, business user can develop, deploy, and manage applications, paying only for the time and capacity that are really used, while scaling up or down to accommodate changing needs or business requirements. The cloud computing brings new forms of the relationship between information processing delegated portfolio and business management. However, information-processing delegation demands more transparency from information processing intermediaries that involve delegated functions and processes. It is obvious that in any delegation process, the delegation transaction is approved or agreed by both parties.
By Lopes and Oliveira (2003) the history of management distribution started in early 1990-s when features such as scalability, flexibility and robustness were identified as necessary for future developments on network management. Further, Goldszmidt and Yemini early supported a management distribution methodology by delegating management operations near management information (Goldszmidt and Yemini, 1998). According to this concept, management processing functions are dynamically delegated to the network elements and executed locally. This introduces a shift in the original concept where the information is transported to a central location to be processed. This approach is known as Management by Delegation and although the research prototypes did not have the expected community recognition, they unquestionably proved the concept. Other approaches for management distributions suggested using mobile agents to implement and distribute management functions.
Delegation has received significant attention from the research community. A number of delegation models have been proposed and most of them are for Role-Based Access Control (Crampton, 2003; Na and Cheon, 2000; Wainer and Kumar, 2005). Delegation operations are usually performed in a distributed manner, meaning that users have certain control on the delegation of their own rights. In order to prevent abuse, some delegation models support specification of authorization rules, which control who can delegate what privileges to other users as well as who can receive what privileges from others. However, in any delegation process, the delegation transaction is approved or agreed by both parties only after both can reach an agreement about the duties or responsibilities of the involved parties. This forms the delegation commitment of the involved parties that can be understood as the course of action about what they have to do before and after the delegation takes place to actually complete the delegation process. Thus, the delegation commitment can include some conditions and constraints on the delegation process, notably duration and service invocation times.
Today’s business dealing with the computerized and networked supply chain and distributed management systems is close to the concept of federated information processing environments, which contain multiple component systems and associated users. Overcoming these problems opens the way to the new sets of collaborative solutions. In this context, information-processing delegation appears to be a potential solution as it provides a tools for maintaining consistency of distributed management system. The basic notions on the terms of delegated processing could be found in the works of Schaad and Moffett (2002), and Crampton and Khambhammettu (2006) which stated two basic types of delegation. The first type of delegation is formal, documented delegation regarding administration (administrative delegation). The second type of delegation is informal, user delegation that is often called ad hoc delegation.
Management distribution is a requirement to modern networks. As features appear and technology evolves, better tools are needed to maintain the network in excellent working condition. Thus, delegation is a powerful mechanism to provide flexible and dynamic access control decisions. Delegation is particularly useful in federated environments where multiple systems, with their own security autonomy, are connected under one common federation. Although many delegation schemes have been studied, current models do not seriously take into account the issue of delegation. The history of management distribution develops system features such as scalability, flexibility and robustness that are necessary for future developments on network management. The actual models are in most cases in the arena of data entry processes. A primary user who is attempting to enter data required for processing may delegate data entry tasks for specific input fields to designated delegate users who are more likely to be knowledgeable about the data to be entered. Data entry operations performed by the primary user are recorded and used to build a transaction model. Further, data entered by the delegate users is merged with data entered by the primary user to meet the requirements of the entire information-processing task. These notions are also encountered within networked data processing systems developed under the terms of distributed, grid and cloud computing architectures. Thus, management distribution is a requirement to modern networks, too.
These issues create an important aspect of delegation models that contain some form of delegation in information processing and management tasks (Pham et al., 2008). Hence, we could state that the delegation is the way by which modern business could manage and process complex, globally distributed information processing that is operationally anticipated by many users dealing with various degrees of authorities.
Security and Privacy Issues of Delegated Information Processing
Every delegated information processing system is under certain security measures that should be done in order to make system fully operational and secure. There are two general approaches in establishing security measures within delegated information processing systems: static enforcement, and dynamic enforcement. In static enforcement, security is ensured by careful design of administrative state. In dynamic enforcement, a verification procedure is performed by the end of the execution of each workflow instance to ensure that the participants have not enhanced their own power through delegation. The advantage of static enforcement is that, if we have already implemented a control system with delegation support, we just need to modify the administrative state to enforce security. There is no need to change the existing implementation. However, static enforcement could make the administrative state more restrictive than necessary. On contrary, in dynamic enforcement, the initial state of the control system is recorded, and the security system maintains a list of the participants for every workflow instance. Dynamic enforcement monitors the usage of delegated privileges rather than placing restrictions on administrative states. It is thus less restrictive and more practical than static enforcement, but introduces a performance overhead in some degree. Besides these technical notions, there are a lot of issues regarding security and trust issues in delegated processing systems, which must be considered.
Delegated information processing asks for new forms and solutions in security and privacy. Information technology and the processing, storage and transmitting of sensitive and personal information is ubiquitous, and as a result of this ubiquity the legal risk and regulatory compliance environment poses increased threats and potential for significant liability. Internal security and privacy professionals find themselves ceding control of significant decisions to third parties and service providers concerning the implementation, maintenance, enhancement and enforcement of information security and privacy measures. Unfortunately, an organization’s legal risk and compliance obligations do not follow, and in most cases, they remain with the organization that chooses to outsource and to delegate business information processing. When we are faced with the delegated information processing, we could find two general areas of security treatment: data, and applications (including business functions and workflow job processes). At the same time, delegated information processing impacts two aspects of how people interact with technologies: how services are consumed, and how services are delivered. Although cloud computing was originally, and still is often associated with Web-based applications that can be accessed by end-users via various devices, it is also very much about applications and services themselves being consumers of cloud-based services. This fundamental change is a result of the transformation brought by the adoption of service-oriented architecture and Web-based industry standards, allowing service-oriented and Web-based resources to become universally accessible on the Internet as on-demand services (Chou, 2010). With delegated information processing, business data and applications of entire organization do not need to reside in the same location, and only parts of functions may reside in the cloud. These issues stipulate the interest in security and privacy within delegated information processing systems.
Legal and information security interests should interact as stakeholders in delegated information processing systems. All of the stakeholders within an organization should be part of the delegation, and those stakeholders, in investigating a potential cloud relationship and in negotiating the terms of a relationship with a cloud provider, should consider and pose the following questions internally and to the vendor, before any contract is signed:
- What kind of data will be in the cloud?
- Where do the data subjects reside?
- Where will the data be stored?
- Will the data be transferred to other locations and, if so, when and where?
- Can certain types of data be restricted to particular geographic areas?
- What is compliance plan for cross-border data transfers?
Further, the critical criterion also exists, and it is crucial in understanding delegated information processing as different portfolio from outsourcing. The key difference between a traditional outsourcing relationship and delegated information processing is consider where the data resides or is processed. For example, in the traditional outsourcing, a company looking to offload some of its data storage would create a dedicated data center and then sell the storage capacity to its clients. The data center might be in another country, but for the most part the client knew where its data was going and where it would be stored and processed. In a cloud environment, geography can lose all meaning, and data may be dispersed across and stored in multiple data centers all over the world. In fact, use of a cloud platform can result in multiple copies of data being stored in different locations. This is true even for a private cloud that is essentially run by a single entity. What this also means is that data in the cloud is often transferred across multiple borders, which can have significant legal implications.
For firms that rely on cloud storage to hold backup data, or essential files, by breaking the services’ code of conduct or terms of usage can have massive repercussions for the end user. When an end user suddenly discovers that the content of their cloud storage has been destroyed, this not only causes the user to become confused, and this could also deepen into a business relations. The risk is rising in the context of backup since the many organizations dealing with delegated information processing does not have their own copies of data. According to Perlow, business in this day and age with multiple computers, mobile devices and Internet access practically everywhere, store the most treasured, important and valuable data in the cloud; to enable them to access it anywhere, and also show others images or other media content which they are proud of (Perlow, 2008).
When cloud storage is used as the primary location of files and documents, a certain trust is left in the hands of the storage provider to ensure that certain steps are taken to prevent data loss and maintain the integrity of the file system (Weiss, 2007). When something affects cloud storage, things can go disastrously wrong for many end users. Whilst data that is stored in the cloud is not actually stored in the cloud, rather a datacenter housing hundreds of servers and thousands of networking cables, physical disasters are one of the greater threats to the cloud. One of the most likely security breaches which could occur, and have massive repercussions on the end user, is malicious and unauthorized access to the users storage or cloud services. An end user’s finances or income could depend on a cloud application to provide services for others; another end user may store sensitive financial data in cloud storage for anywhere and everywhere access. By accessing their cloud without authorization using credentials without their knowledge, is not only fraud and could result in criminal charges being brought, it could also have a severe negative impact on the end users, and those of which the end user relies on. The business that relies on delegated information processing should encounter three fundamental issues. First, sensitive data should be defined and appropriately encrypted to the client’s satisfaction. Second, to be allowed to process this sensitive data, processing systems must provide satisfactory evidence of encrypted data processing and application integrity. Third, cloud computing providers must create the ability to regionally restrict the location of data, or the client may begin refusing to buy cloud computing services that do not certify the allowed regional locations of data.
Since the delegated information processing is different from outsourcing that has some forms of standard security and privacy terms of compliance, there is pressure on delegated information processing stakeholders to begin to build standards and processes to create security and trust. Several efforts were done in developing standards such as the SNIA Cloud Data Management Interface specification, the Data Integrity Field standard, WS-Reliability and WS-Transaction protocols as well as XML-based solutions that add some transaction management functionality to Web applications. As these standards and solutions mature, it may be appropriate to make them contractual.
Further, reliable business records are necessary to collect a bill, prove an obligation, comply with government requirements, or establish a sequence of disputed events. If there are serious questions about data integrity in the systems routinely used by the business, the company may find its position badly undermined. As transactions databases and other kinds of business records follow email into the cloud, there are more disputes over records authentication and reliability. This suggests that organizations dealing with delegated information processing should seek out computing service providers that offer effective data integrity as well as security. They should also consider inserting a general contractual obligation for the service provider to cooperate as necessary in legal and regulatory proceedings. In conclusion, the business user should always consider security regarding logical security, privacy, and legal issues in delegated information processing arena.
Conclusion
To summarize, the text presents the emergence of grid and cloud computing as a platforms for next-generation parallel and distributed computing deployed through the delegated information processing systems. Furthermore, various challenges in definition, managing, and securing delegated information processing has been identified. Hence, it is obvious that business ecosystems evolve by new information technology that fosters the information-communications ecosystem deployment. Information-communications ecosystem crosses business domains and different computer systems without single functional reference model. Since it is not feasible to define all the required functional models, the ecosystem model was presented by schematic diagram of interconnectivity and interfunctionality of core categories born in cloud computing environment. Further, the mutual benefit of distributed, grid, and cloud computing is presented by information-communications system development paradigm – delegated information processing.
Findings suggest that while significant efforts have been devoted to the development of grid technologies and cloud computing platforms, still more must be achieved in terms of delegated computing. The resource management system of delegated information processing must dynamically provide the best resources according to a metric of the price and performance available, and schedule computations on these resources such that they meet business user requirements. There are also security and privacy issues that must be encountered in each system design process ensuring that the business goals will be met in compliance with the current laws, regulation and business codes.
The current literature shows enough facts about grid and cloud computing. At the same time, however, it lacks vital insights into deployment of delegation concept that is of crucial importance for distributed processing implementation within information -communications infrastructure available today. This notion is the basis for introducing delegated information processing as a tool for modern business to achieve the most from technology, and enabling information processing available every time and everywhere to all of employees with less cost, management efforts and organizational obstacles. Thus, when the grid and cloud computing are in place, the delegation of management is logical movement into system integrity over the virtualized, networked, and embedded resources. These issues present the subject for further research in order to better explore the scope, possibilities, and obstacles in delegated information processing deployment.
References
Blythe, J., Deelman, E., Gil, Y., Kesselman, C., Agarwal, A., Mehta, A. & Vahi, K. (2003). “The Role of Planning in Grid Computing,” Proceedings of the 13th International Conference on Automated Planning and Scheduling, ISBN 1-57735-187-8, 9-13 June 2003, Trento, Italy, 153-163.
Publisher – Google Scholar
Buyya, R., Yeo, C. S. & Venugopal, S. (2008). “Market-Oriented Cloud Computing: Vision, Hype, and Reality for Delivering IT Services as Computing Utilities,” Proceedings of 10th IEEE International Conference on High Performance Computing and Communications, ISBN: 978-0-7695-3352-0, 25-27 September 2008, Dalian, China, 5-13.
Publisher – Google Scholar
Buyya, R., Yeo, C. S., Venugopal, S., Broberg, J. & Brandic, I. (2009). “Cloud Computing and Emerging IT Platforms: Vision, Hype, and Reality for Delivering Computing as the 5th Utility,” Future Generation Computer Systems, 25(6). 599-616.
Publisher – Google Scholar
Chou, D. (2010). “Understanding Cloud Computing and Cloud-Based Security,” SOA Magazine, 37:2.
Publisher
Crampton, J. (2003). “On Permissions, Inheritance and Role Hierarchies,” Proceedings of the 10th ACM Conference on Computer and Communications Security, ISBN: 1-58113-738-9, 27-30 October 2003, Washington, DC, USA, 85-92.
Publisher – Google Scholar
Crampton, J. & Khambhammettu, H. (2006). “Delegation in Role-Based Access Control,” Proceedings of the 11th European Symposium on Research in Computer Security, ISBN: 978-3-540-44601-9, 18-20 September 2006, Hamburg, Germany, 174-191.
Publisher – Google Scholar – British Library Direct
Di Costanzo, A., Assuncao, M. D. & Buyya, R. (2009). “Harnessing Cloud Technologies for a Virtualized Distributed Computing Infrastructure,” IEEE Internet Computing, 13(5). 24-33.
Publisher – Google Scholar
Foster, I., Kesselman, C., Jeffrey M. N. & Tuecke, S. (2002). “Grid Services for Distributed System Integration,”Computer, 35(6). 37-46.
Publisher – Google Scholar – British Library Direct
Foster, I., Kesselman, C. & Tuecke, S. (2001). “The Anatomy of the Grid: Enabling Scalable Virtual Organization,”International Journal of High Performance Computing Applications, 15(3). 200-222.
Publisher – Google Scholar – British Library Direct
Foster, I. & Kesselman, K. (1998). ‘Computational Grids, The Grid: Blueprint for a New Computing Infrastructure,’ Foster, I. and Kesselman, K. (eds). Morgan Kaufmann, San Francisco.
Google Scholar
Goldszmidt, G. & Yemini, Y. (1998). “Delegated Agents for Network Management,” IEEE Communications Magazine, 36(3). 66-71.
Publisher – Google Scholar – British Library Direct
Goyal, B. & Lawande, S. (2005). Grid Revolution: An Introduction to Enterprise Grid Computing, McGraw-Hill, Emeryville.
Publisher – Google Scholar
Grimshaw, A. S. & Natrajan, A. (2005). “Legion: Lessons Learned Building a Grid Operating System,” Proceedings of the IEEE, 93(3). 589-603.
Publisher – Google Scholar
Grüner, H. P. (2009). “Information Technology: Efficient Restructuring and the Productivity Puzzle,” Journal of Economic Behavior & Organization, 72(3). 916-929.
Publisher – Google Scholar – British Library Direct
Jeffery, K. (2002). Data Management Challenges for GRID Computing, Springer, Berlin.
Publisher – Google Scholar – British Library Direct
Keahey, K., Foster, I., Freeman, T. & Zhang, X. (2005). “Virtual Workspaces: Achieving Quality of Service and Quality of Life in the Grids,” Scientific Programming, 13 (4). 265-275.
Publisher – Google Scholar – British Library Direct
Kumar, A. (2005). “Distributed System Development Using Web Service and Enterprise Java Beans,” Proceedings of the 2005 IEEE International Conference on Services Computing (volume 2). ISBN 0-7695-2408-7, 11-15 July 2005, Orlando, Florida, 23-24.
Publisher – Google Scholar
Lopes, R. & Oliveira, J. (2003). Delegation of Expressions for Distributed SNMP Information Processing, Integrated Network Management VIII: Managing It All, Goldszmidt, G. and Schönwälder, J. (eds). Kluwer Academic Publishers, Boston, 395- 408.
Publisher – Google Scholar
Mather, T., Kumaraswamy, S. & Latif, S. (2009). Cloud Security and Privacy: An Enterprise Perspective on Risks and Compliance, O’Reilly Media, Sebastopol.
Publisher – Google Scholar
Na, S. & Cheon, S. (2000). “Role Delegation in Role-Based Access Control,” Proceedings of the fifth ACM workshop on Role-Based Access Control, ISBN: 1-58113-259-X, 26-27 July 2000, Berlin, Germany, 39-44.
Publisher – Google Scholar
Perlow, J. (2008). “Preparing for a Flickr Apocalypse,” Available at: http://blogs.zdnet.com/perlow/?p=9316 [Accessed 8th November 2009].
Publisher
Pham, Q., Reid, J., McCullagh, A. & Dawson, E. (2008). “Commitment Issues in Delegation Process,” Proceedings of the Sixth Australasian Information Security Conference, ISBN: 978-1-920682-62-0, 22-25 January 2008, Wollongong, NSW, Australia, 27-38.
Publisher – Google Scholar
Rittinghouse, J. W. & Ransome, J. F. (2010). Cloud Computing: Implementation, Management, and Security, CRC Press, Boca Raton.
Publisher – Google Scholar
Schaad, A. & Moffett, J. D. (2002). “A Framework for Organizational Control Principles,” Proceeding of the 18th Annual Computer Security Applications Conference, ISBN 0-7695-1828-1, 9-13 December 2002, Las Vegas, Nevada, 229-238.
Publisher – Google Scholar
Smarr, L. & Catlett, C. E. (1992). “Metacomputing,” Communications of the ACM, 35(6). 44-52.
Publisher – Google Scholar
Stanoevska-Slabeva, K., Wozniak, T. & Ristol, S. (2010). Grid and Cloud Computing: A Business Perspective on Technology and Applications, Springer Verlag, Berlin.
Google Scholar
Vaquero, L., Rodero-Merino, L., Caceres, J. & Lindner, M. (2009). “A Break in the Clouds: Towards a Cloud Definition,”ACM SIGCOMM Computer Communication Review, 39(1). 50-55.
Publisher – Google Scholar
Velte, A., Velte, T. & Elsenpeter, R. (2009). Cloud Computing: A Practical Approach, McGraw-Hill, New York.
Publisher – Google Scholar
Wainer, J. & Kumar, A. (2005). “A Fine-Grained, Controllable, User-to-user Delegation Method in RBAC,” Proceedings of the tenth ACM symposium on Access control models and technologies, ISBN: 1-59593-045-0, 1-3, June 2005, Stockholm, Sweden, 59-66.
Publisher – Google Scholar
Weiss, A. (2007) “Computing in the Clouds,” netWorker, 11(4). 16-25.
Publisher – Google Scholar
Westerinen, A. & Bumpus, W. (2003). “The Continuing Evolution of Distributed Systems Management,” IEICETransactions on Information and Systems, 86(11). 2256-2261.
Publisher – Google Scholar – British Library Direct
Yabandeh, M., Knezevic, K., Kostic, D. & Kuncak, V. (2010). “Predicting and Preventing Inconsistencies in Deployed Distributed Systems,” ACM Transactions on Computer Systems, 28(1):2.
Publisher – Google Scholar