Department of Informatics, Faculty of Business and Management (FBM), Brno University of Technology (BUT), Brno, Czech Republic
Volume 2016 (2016),
Article ID 445849,
Journal of Eastern Europe Research in Business and Economics,
8 pages,
DOI: 10.5171/2016.445849
Received date: 27 February 2014; Accepted date: 15 July 2014; Published date: 11 February 2016
Cite this Article as:
Karel Doubravský and Radek Doskočil (2016), “ Determination of Client Profitability under Uncertainty Based on Decision Tree ”, Journal of Eastern Europe Research in Business & Economics, Vol. 2016 (2016), Article ID 445849, DOI: 10.5171/2016.445849
Complex decision making tasks of different natures, e.g. identifying of a profitability of a client in the insurance business, are based on vague, sparse, partially inconsistent and subjective knowledge of experts. One important problem related to realistic decision making tasks is uncertainty in input data / information. Decision-making under these conditions is difficult and can lead to incorrect results (decisions). The aim of this paper is to present an easy approach of how to identify profitability of the client in insurance business under the condition of input data uncertainty. The solution to the decision-making problem is based on the decision to extend or renew an insurance contract for next period (concretely two years). The solution of this problem is based on the decision-making task, which is graphically represented by a decision tree. This decision problem is solved for a fictitious client, but the required data sets are based on real data sets. The case study is represented by a tree with three lotteries, three decisions and seven terminals. The results arising from the paper serve mainly for needs of insurance companies. The main contribution of this paper is using a decision tree to provide managers with the tool to support decision-making and information about expected client profitability for the next period and its confidence interval.
Keywords: Insurance business, decision-making, decision tree, uncertainty of information.
Introduction
In practice, there is a broad spectrum of decision-making tasks, e.g. insurance business, economics, engineering, politics, etc., see e.g. (Dondi et al, 2014; Vats et al, 2014; Daniel et al, 2002; Hodouin, 2011; Maroney et al, 2008; Vasebi et al, 2012). These realistic decision-making tasks are often limited by available input information.
Extensive realistic industrial decision-making applications, such as chemical, petrochemical, food processes, are faced with the problem of inaccurate measurements, e.g. concentrations, flow-rates, etc., see e.g. (Thipwiwatpotjana and Lodwick, 2014). In practice, most factories are outdated and have therefore poor control systems that require an integration of vague heuristics and all available inaccurate measurements, see .e.g. (Dohnal and Sabadi, 2006).
Insurance business, economics and sociological / psychological decision-making applications are usually faced with vague, inconsistent input information, see e.g. (Daniel et al, 2002; Saïs and Thomopoulos, 2014). The same problem occurs when selecting new technologies based on appropriate and suitable criteria with respect to a particular developing country, see .e.g. (Vats et al 2014). Vague information is often described by fuzzy sets, see e.g. (Ciavolino et al, 2014; Yadav et al, 2014).
Most of the above noted decision tasks can be represented by single root trees, i.e. decision trees, and sets of available input information, such as probabilities, profitability, penalties, plausibility, etc., see e.g. (Thipwiwatpotjana and Lodwick, 2014). From the preceding text, it is apparent that there are two main problems (lack and uncertainty) of input information in the real-world., see e.g. (Kuzilek et al, 2014; Qin et al, 2014).
Lack of information is usually based on the usage of meta-heuristics; this is not the subject of this article, see e.g. (Bradshaw, 2000; Jegadeesh et al, 2004; Kubíčková et al, 2013).
Information uncertainty, i.e. there is unique, sparse, vague, partially inconsistent information, e.g. probabilities, profitability, penalties, etc., is a significant decision-making problem. Decisions are made under information shortage; therefore classical statistical methods are not applicable, see .e.g. (Spanos, 2010). If uncertainties cannot be quantified in a simple probabilistic way, then the topic of possibility decision theory is often a natural one to consider, see e.g. (Fargier et al, 2012; Dubois, 2014). In many studies, the problem of information uncertainty is handled using fuzzy sets, e.g. fuzzy numbers, see .e.g. (Dohnal and Sabadi, 2006; Dubois et al, 2013; Lee et al, 2011; Pedrycz et al, 2014; Zeinalkhani and Eftekhari, 2014).
The aim of this paper is to present an easy approach of how to identify profitability of the client in insurance business under the condition of input data uncertainty. The proposed easy approach is based on simulation method (Monte Carlo method), decision tree topology and experts’ estimates about probabilities and profitability.
The rest of the paper is organized as follows. The next section discusses the relevant methods. This section is followed by a case study. The final section presents some important issues and implications for future research.
Materials and methods
Creditworthiness criteria
In many insurance companies the profitability of the client is determined only by existing clients. The potential client is generally regarded as creditworthy. If there are the negative signals of the client then a detailed analysis is performed. This analysis includes evaluating the creditworthiness of the client’s particular client according to the following criteria:
Loss ratio is the ratio of the insurance claims and the earned premiums. Loss ratio is a very important factor in assessing the creditworthiness of the client. The higher the value of the loss ratio of the client is, the worse the creditworthiness of the client and conversely. In practice, The maximum value of loss ratio into 75% is often recommended. The client is unattractive over this value. The creditworthiness of the client is low and threatening in extreme cases his reject. It is necessary to add the next administrative costs (costs associated with the administration of insurance contracts and in particular their closure including the remuneration of intermediaries, etc.) in the amount least 20% to the value 75%.
Payment discipline is a historical view of the repayment premium. The insurance contract is terminated if the premium is not paying. The process of termination of the insurance contract shall be governed by the conditions laid down in the insurance contract. These conditions may be different in individual insurance companies.(Přečková, 2014)
Insurance penetration is the ratio of the insurance risks and the existing (real) risks. (Penetration is not understood in a macroeconomic sense as a ratio of earned premiums to GDP.) The higher the value of the insurance penetration of the client is, the better the creditworthiness of the client and conversely. (Shang and Chung, 2014)
Identifying the profitability of the client represents the process of evaluation of the pros and cons mostly by subjective opinions of the decision maker. This implies the risk of erroneous decisions caused by the human factor. The practical experience and the next abilities and skills of the evaluator in the decision problem occupied the significant role (Sun and Guo, 2013). Accuracy of this process has a direct impact on the marketing activities of insurance companies (Shang and Chung, 2014).
Decision tree evaluation
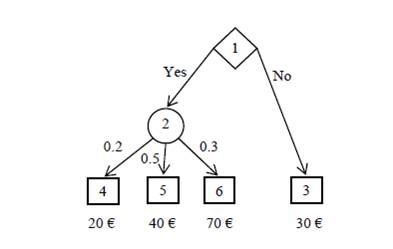
A decision tree has one root node, see e.g. node 1 in Fig. 1, where circles represent lotteries, boxes represent terminals and diamond represents a decision.(Rose, 1976; Welpe, 2014)
Figure 1: Decision tree (Source: own processing)
The following definitions are used below:
J Set of all decision nodes, see e.g. node 1, Fig.1. I Set of all lotteries, see e.g. node 2, Fig.1. (1) T Set of all terminals, see e.g. nodes 3, 4, 5 and 6, Fig.1.
Let us consider Si, for i ∈ I, is the set of all situations of ith node (lottery)
Si = {sik, k = 1, 2, … , K}, (2)
where K is number of all situation of ith node (lottery), see e.g. S2 = {s2k, k = 1, 2, 3} (branches 2—4, 2—5 and 2—6), Fig.1.
Situations (2) probabilities of ith node (lottery) is the column vector
p(Si) = [p(si1), p(si2), … , p(sik)]T, k = 1,2, … ,K, i ∈ I, (3)
see e.g. p(S2) = [0.2, 0.5, 0.3]T, Fig.1.
Valuation, e.g. profitability, all situations of ith lottery for certain decision node j is the vector
where k = 1,2, … ,K, i ∈ I and j ∈ J, see .e.g. x(S2;1) = [20, 40, 70], Fig.1. Valuation edges (branches) containing situation node is determined by an expected value, see (Welpe, 2014), of some random variable Z, e.g. profitability. This expected value can be written with relations (1)—(4) as follows:
E(Z|ji) = x(Si; j)-p(Si), (5)
see e.g. E(Z|12) = [20,40,70]-[0.2, 0.5, 0.3]T = 20-0.2 + 40-0.5 + 70-0.3 = 45, Fig.1.
Expected value (5) is compared with the valuation of edges (branches) without situation nodes, denoted xt for t ∈ T. Expected value E(Z|12) =45 € is greater than x3 = 30 €, according to the rule of maximizing profit, see (Welpe 2014), the decision is Yes.
Probabilities (3) and valuation (4) can be entered as experts’ estimates by lower and upper boundary, e.g. probability is from 0.15 to 0.25, profitability is from 30 to 45 €, etc. then expected value (5) is difficult to solve. Assuming that the probability and profitability is random variable, denoted V, then lower and upper boundary is
V ∈ [VL; VU]. (6)
The simulation method, e.g. Monte Carlo method, see (Tan et al, 2014; Chi and Beerli, 2014), may be used for determining (5). From interval (6), a value v is randomly generated and this value enters to relation (5).
Results
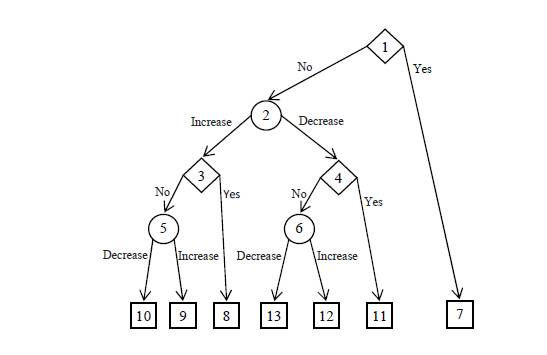
Case study describes the decision-making problem to extend or renew an insurance contract for next period (concretely two years). The solution of this problem is based on the decision-making task, which is graphically illustrated by a decision tree, see Fig. 2. The decision tree has five levels and three kinds of nodes — decision nodes (nodes number 1, 3 and 4), situation (lottery) nodes (nodes number 2, 5 and 6) and terminal nodes (nodes number 7, 8, 9, 10, 11, 12 and 13).
Figure 2: Decision tree (Source: own processing)
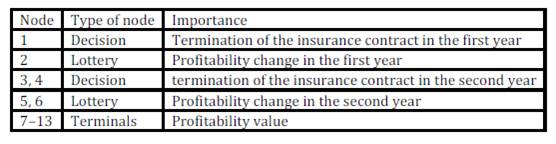
In the next table (Tab. 1) the importance of the main knots of the chart is described.
Table 1: Importance of branches (Source: own processing)
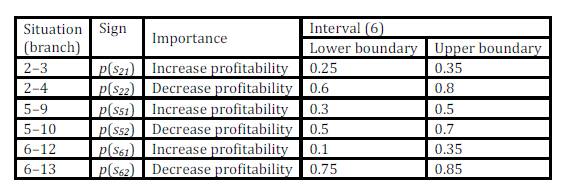
Decision nodes are nodes under management control, situation nodes (lotteries) are not under management control and terminals are possible results. The next table (Tab. 2) shows experts’ estimates (lower and upper boundary) of situations’ probabilities (nodes following the lottery).
Table 2: Probability estimates (Source: own processing)
The next table (Tab. 3) shows experts’ estimates (lower and upper boundary) of situations’ profitability (nodes following the lottery).
Table 3: Profitability estimates (Source: own processing)
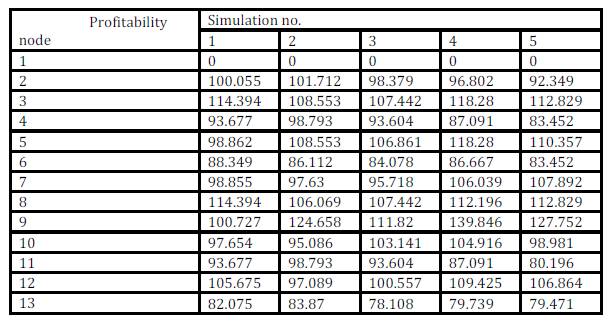
The following part presents the solving of the decision-making problem using Monte Carlo methods. For each situation, values of probabilities and profitability are generated, see intervals (6) Tab. 2 and Tab. 3. Generated values of probabilities form the vector (3), values of profitability form the vector (4). These vectors form the basis for calculating the expected values (5) of profitability of each decision node 1, 3, 4, see Fig. 1. The obtained expected values of profitability are compared with values of profitability x7, x8 and x11, see Tab. 3, which are generated too. This comparison leads to relevant decision. The above procedure is repeated 100 times. The first five simulations are shown in the next table (Tab. 4).
Table 4: First five simulations (Source: own processing)
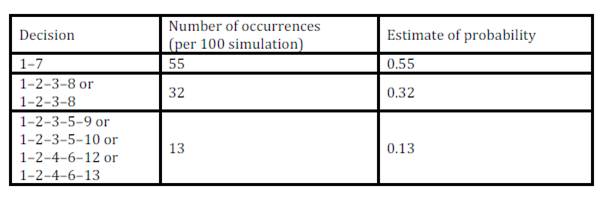
Table 5 shows identifying decisions and their estimates of probabilities. Decision 1—7 has probability 0.55, decision 1—2 has probability 0.45 (sum of 0.32 and 0.13).
Table 5: Profitability estimates (Source: own processing)
Because the probability of decision 1—7 is greater than decision 1—2, the final decision is the termination of the insurance contract in the first year. Minimum profitability value of this decision is 94.91 € and maximum value is 109.90 €. These values can be simply interpreted as follows; value of profitability can be expected with confidence 55 % from interval [94.91 €; 109.90 €].
Conclusion
The paper solves probably the most difficult decision-making problem related to the uncertainties of input information, namely the decision to extend or renew an insurance contract for the next period (concretely two years). The solution of this problem is based on the decision-making task, which is graphically illustrated by a decision tree. The main contribution of this paper is the easy approach of how to identify profitability of the client in insurance business under the condition of input data uncertainty. The proposed easy approach is based on simulation method (Monte Carlo method), decision tree topology and experts’ estimates about probabilities and profitability.
The advantage of this approach lies in the fact that it allows easy results for large decision-making problems under input information uncertainty. It also allows to simply incorporate risk aversion of the decision-maker, e.g. management and allows the decision-maker to have flexible control over decision-making problems and perform sensitivity analyses. The limitation of the proposed approach is the need to build decision tree (it can be large).
Acknowledgments
This paper was supported by grants FP-S-15-2787 “Effective Use of ICT and Quantitative Methods for Business Processes Optimization” from the Internal Grant Agency at Brno University of Technology.
References
1. Bradshaw, MT., (2000), How Do Analysts Use Their Earnings Forecasts in Generating Stock Recommendations? Social Science Research Network, Rochester, NY.
6. Dohnal, M. and Sabadi, R., (2006), ‘Fuzzy mass balances of sugar factory flowsheets’, INTERNATIONAL CONGRESS OF CHEMICAL AND PROCESS ENGINEERING. Prague, p P5.125.
9. Dubois, D., Fargier, H. and Guyonnet, D., (2013), Data Reconciliation under Fuzzy Constraints in Material Flow Analysis. doi: 10.2991/eusflat.2013.4 Googlescholar
10. Fargier, H., Amor, NB. and Guezguez, W., (2012), On the Complexity of Decision Making in Possibilistic Decision Trees. CoRR arXiv: 1202.3718. Googlescholar
18. Přečková, L., (2014), ‘How do insurance companies inform their clients of insured value within business insurance against natural disasters in the Czech Republic?’, Proceedings of 14th International Conference on Finance and Banking. Silesian university in Opava, Opava, pp 359—371.
20. Rose, L.M. (1976) Engineering investment decisions: planning under uncertainty. Elsevier Scientific Pub. Co.”¯: Distributors for the U.S. and Canada, Elsevier / North Holland, Amsterdam; New York
24. Sun, S. and Guo, W., (2013), ‘Research of Insurance Business Process Outsourcing Benefits, Models and Risks’, Proceedings of 2013 China International Conference on Insurance and Risk Management. Tsinghua University Press, Tsinghua, pp 208—214.